| ISSN 1661-1802 |
| | Numéro courant| Présentation| Instructions aux auteurs| Anciens numéros| |
| Editorial | Etudes et Recherches | Comptes-rendus d'expériences | Evenements | Ouvrages parus |
Eléments darchitecture pour une mémoire dentreprise orientée processus métierPar: Mahmoud Brahimi et Laid Bouzidi |
Résumé |
|||||||||||||||||||||||||
|
Les entreprises disposent dun capital de connaissances (documents, données, référentiels, messages, ) souvent mal exploité notamment durant lexécution des processus métiers. A cela, plusieurs raisons peuvent être invoquées : des workflows peu ou pas automatisés, une exploitation très réduite de ces connaissances car seules les données sont principalement utilisées, labsence darchitecture qui pourraient fédérer ou intégrer tous ces connaissances en vue dune utilisation efficace. En outre, on constate que ces connaissances sont très peu reliées aux processus métier. De nombreuses tentatives ont vu le jour pour tenter de juguler ce manque de gestion de ce capital, à travers des systèmes de gestion de connaissances, de portails (intranet), ou plus largement par des mémoires dentreprises. Toutefois de nombreuses préoccupations restent encore en suspens. Quelles sont les connaissances liées à un processus métier ? Quel est lapport dune mémoire dentreprise pour lexécution des processus métiers ? Comment considérer les liens entre les connaissances ? Quelles architectures génériques est-il possible denvisager pour la construction des mémoires dentreprise ? Voilà les questions auxquelles cet article tente de répondre. Mots-Clés : mémoire dentreprise, processus métier, connaissances, architecture, documentation. |
|||||||||||||||||||||||||
Abstract |
|||||||||||||||||||||||||
|
Enterprises have got a huge amount of knowledge (documents, data, emails, ) which is often bad treated particularly when a business process is executed. Several reasons motivate this fact among them: few or no automated workflow, exploitation limited of this knowledge because only data are mainly used, the lack of framework capable to federate or integrate all kind of knowledge for an efficient use. . In addition we observe that knowledge is not really linked with business processes. Several temptations were made in order to reduce this insufficiency of capital management using knowledge management systems, intranet, or more generally corporate memories. However many problems still require new solutions. What is knowledge linked to business process? Which is the contribution of corporate memories in the processes execution? How to considerer the link between knowledge? What are the generic architectures that can be envisaged for corporate memory building? These are the questions that this paper attempts to answer. Keywords : memory, business process, knowledge, architecture, documentation |
|||||||||||||||||||||||||
I. Introduction :
« La gestion des connaissances désigne la gestion de lensemble des savoirs et savoir-faire en action mobilisés par les acteurs de lentreprise pour lui permettre datteindre ses objectifs » (Charlet et al, 1999). Plusieurs étapes ont été identifiées dans un processus de gestion de connaissances : il sagit de lexplicitation de connaissances tacites repérées comme cruciales pour lentreprise, du partage du capital des connaissances rendu explicite sous forme de mémoire et de lappropriation et de lexploitation dune partie de ces connaissances par les acteurs de lentreprise (Nonaka et Takeuchi, 1995). Larchitecture décisionnelle autour de laquelle sont bâtis les systèmes daide à la décision assure le processus de transformation des données en informations à usage décisionnelle (Lebraty, 2000). Ces informations à usage décisionnel contribuent à lamélioration des performances des savoir-faire structurés sous forme de processus métiers, et la connaissance contenue dans les ressources utilisées apporte des moyens pour lamélioration de la prise de décisions. Cette prise de décision est fortement dépendante des informations et des connaissances qui vont servir de support à cette décision et des outils et des méthodes entrant dans lexécution des processus. En effet, une décision est le fruit de lutilisation dun ensemble dinformations et de connaissances interprétées dans un contexte bien précis. Aussi, certaines catégories de processus peuvent faire appel au même ensemble doutils et de méthodes, dont la mise en uvre comporte de nombreux paramètres. Elles nécessitent de prendre des décisions sur le choix des outils et des méthodes dont la qualité influera fortement sur celle du processus. Lamélioration du processus va alors reposer principalement sur lamélioration des décisions dans lapplication de ces outils et méthodes. Les acteurs sappuient pour cela sur des connaissances acquises antérieurement par dautres et matérialisées sous forme de mémoires dentreprise. 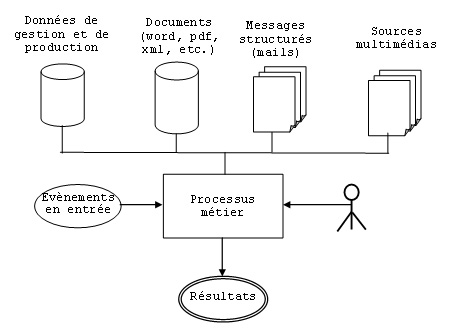
II. Connaissances liées aux processusLa définition de référence des processus est aujourdhui celle qui est donnée par la norme ISO9000 :2000. Cest « un ensemble dactivités corrélées ou interactives qui transforme des éléments dentrée en éléments de sortie ». Cette définition est succincte, ce qui autorise une application très large. On peut donner la définition suivante dans le cadre dun processus métier : « un processus métier est un ensemble dactivités, entreprises dans un objectif déterminé. La responsabilité dexécution de tout ou partie des activités par un acteur correspond à un rôle. Le déroulement du processus utilise des ressources et peut être conditionné par des événements, dorigine interne ou externe. Lagencement des activités correspond à la structure du processus ».
Un processus métier organise le travail des acteurs pour répondre à des objectifs définis par la stratégie de lorganisation; lobjectif étant lexpression de la finalité du processus.
Cependant, les dispositions damélioration peuvent avoir des effets contradictoires. Ainsi, laugmentation de la flexibilité est souvent coûteuse. Une plus grande efficacité entraîne parfois une rigidité accrue. Une focalisation sur les coûts et lefficience peut se faire au détriment de la relation client, de lefficacité et de la flexibilité. Lorientation du choix du vecteur damélioration et des actions conduisant à lévolution du processus nécessite le ciblage sur une catégorie dobjectif considérée comme la plus importante pour lorganisation. II.1. Description des connaissancesLa définition du processus métier telle quénoncée plus haut précise que lexécution dun processus par les acteurs de lorganisation nécessite le savoir-faire de ces derniers matérialisés sous forme de connaissances tacites ou explicites. Il nécessite aussi lutilisation des ressources qui se résument en un ensemble de moyens, dinformations et doutils nécessaires au déroulement des activités du processus. Ces ressources, matérialisées sous forme de documents, données du système dinformation, e-mails, messages vidéo, messages audio, etc , renferment des connaissances et des informations utiles et nécessaires pour lexécution des processus et quil faudra capturer et intégrer dans des mémoires dentreprise en utilisant les méthodes issues de lingénierie des connaissances. Une fois intégrées, ces informations et connaissances sont souvent diffuser via les intranets des entreprises et permettent ainsi dêtre des sources importantes pour guider et orienter les acteurs de lorganisation tout au long de lexécution du processus et améliorent, au fil du temps, les indicateurs de performance de ces derniers (figure 2). 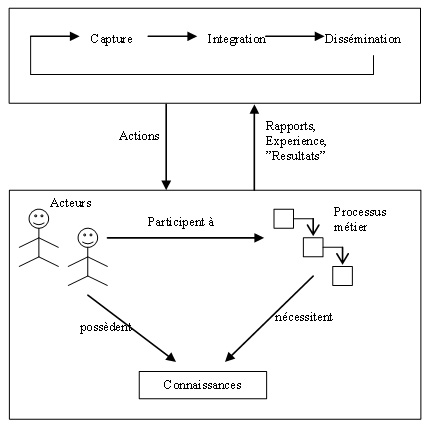
II.2 Réseaux de connaissances et représentationLa perception de ce quest ou devrait être une représentation de connaissances sest nettement affinée au cours des dernières années, voir synthèse dans [Davis 93]. Parmi les formalismes généraux de représentation des connaissances proposés dans la littérature :
Plus récemment, dautres langages, associés à une syntaxe XML, sont apparus avec lémergence du web sémantique [Dieng 02] : RDF, RDFS, OWL, XTM
Lintérêt dune représentation en graphe est de pouvoir effectuer le même type de raisonnement sur les différentes sources de données (recherche de chemin, recherche déléments, vérification de propriétés, recherche de similarité, etc.) et de pouvoir exprimer les liens entre les sources de manière uniforme. Nous obtenons ainsi un réseau de graphe dans lequel les liens permettent le passage dun graphe dune source à un autre graphe dune autre source. Formellement, soit G1={S1, T1} et G2={S2,T2}, 2 graphes pour 2 sources de données, alors on peut définir un réseau R={Sr, Tr} construit tel que P1(Sr) ⊆ S1 et P2(Sr) ⊆ S2, Pi est une partie de R. Tr est lensemble des liens Lr tel que une élément de Lr relie 2 sommets de G1 et G2. Le réseau de connaissances ainsi construit est alors un support pour les processus métier en vue daccéder aux informations nécessaires à son exécution. Laccès à un élément dinformation appartenant à une source quelconque va entraîner la recherche dautres informations appartenant à dautres sources grâce à une navigation dans le réseau de connaissances. Parmi de nombreuses approches de modélisation des connaissances les ontologies sont apparues comme un outil incontestable de modélisation des connaissances du domaine. Rappelons qu'une ontologie est une description des concepts et des relations caractérisant un domaine. Plusieurs ontologies de domaine ont été développées dans différents secteurs d'activité. Ainsi, l'utilisation des ontologies pour la modélisation des connaissances du domaine s'est vue croître ces dernières années notamment dans les domaines suivants: médecine, biologie, environnement, tourisme et domaine juridique. Dun point de vue formel, une ontologie de ramène à une représentation et manipulation de graphes (ou de réseaux). II.3. Représentation des processus métier
La description des processus métiers peut se faire sous forme de texte et/ou sous forme dillustrations. Cependant, la communication, est un enjeu important dans les études sur les processus à tous les stades des travaux. Plusieurs acteurs ayant des cultures et des préoccupations différentes sont impliqués dans ces travaux. Lutilisation de formalismes partagés par une communauté dacteurs facilite la communication, épargne leffort dexplicitation des termes méthodologiques employés et guide le modélisateur dans la sélection déléments clés à faire figurer. Chaque méthode fournit une collection de modèles, de digrammes et une démarche plus ou moins adaptée aux besoins dun projet particulier. Lapplication stricte des méthodes a laissé la place à une utilisation plus pragmatique des modèles et diagrammes en fonction des besoins rencontrés. Les acteurs chargés de décrire et daméliorer un système, ont maintenant une « boite à outil » dans laquelle ils peuvent trouver le formalisme adapté à la réalisation de leur tâche. Lavantage de tels réseaux est de pouvoir effectuer un certain nombre de vérifications qui pourraient mettre en avant des dysfonctionnements des processus tel que les inter-blocages par exemple. Par ailleurs, lextension des RdP pour préciser les conditions de déclenchement des transitions est possible. En loccurrence, pour un processus métier, le déclenchement dune de ses transitions peut être soumis à un déclenchement manuel que réaliserait un acteur lorsquil aura pris connaissance des informations nécessaires à lexécution de la transition. Des expressions logiques peuvent également être attachées aux transitions. Leur évaluation peut être élaborée à partir de lagrégation dinformation multi-sources. II.4. Connexion processus connaissancesLexécution du processus nécessite des informations provenant de sources hétérogènes. Le déclenchement dune activité est toujours conditionnel. Il nécessite larrivée dévènements, représentée par la production de jetons dans les places, mais doit être validé par lexpert lorsquil prend connaissances des informations provenant des sources de données, de documents, de messages, etc. Cette validation est représentée par des liens (arcs du RdP) que lon peut qualifié dexogènes, par rapport aux arcs (natifs) du RdP que nous qualifierons dendogènes. Dans la figure 3, on notera que le processus représenté par une activité (la transition du RdP) nécessite un jeton sur la place en entrée mais également la validation des informations provenant du réseau de connaissances constitué : 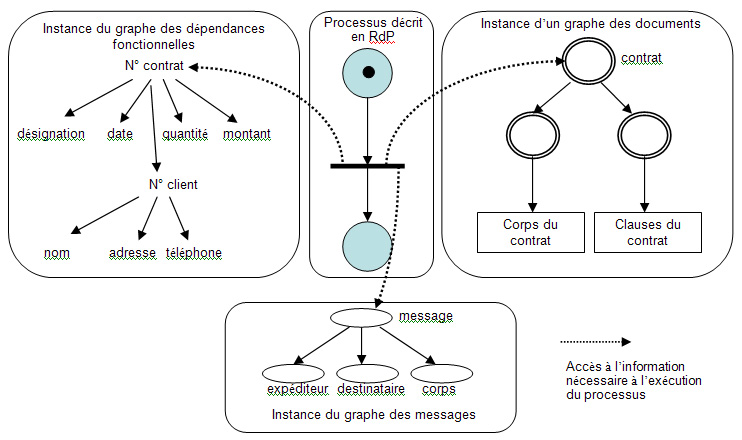
III. Proposition dune architecture dune mémoire dentrepriseCette section consacrée au cur de notre proposition commence par présenter une étude de cas qui met en évidence la nécessité, pour les entreprises, de disposer dun outil fédérateur capable dinterroger simultanément et « intelligemment » les sources de connaissances dune entreprise à travers divers supports que sont les bases de données, les serveurs de messageries, les bases de documents, etc. La proposition darchitecture dune mémoire dentreprise orientée processus métier que nous faisons vise à prendre en charge les outils qui permettent doffrir la « bonne information » aux acteurs des processus. III.1. Etude de casUne société de négoce international en produits agricoles et alimentaires, qui assure deux métiers principaux : le négoce et le courtage Ces deux métiers, aux finalités très différentes, sont effectués par un même intervenant au sein de la société. En effet, dans une même journée, il peut être à la fois courtier et négociant. Cette situation peut aller jusqu'à "convertir" un contrat de courtage en contrat de négoce. La société est donc extrêmement souple au niveau de son activité. La finalité majeure est :
Nous considérons ici le processus daffrètement qui consiste à établir les contrats de transport (fixant le prix, la quantité, le point d'enlèvement, le point de destination, la date d'enlèvement, etc,).
Les messages
Les documents
Les données
Cette société sappuie sur le modèle de données suivant (figure 4), illustré par son modèle logique, pour gérer les données de gestion et les données métiers.
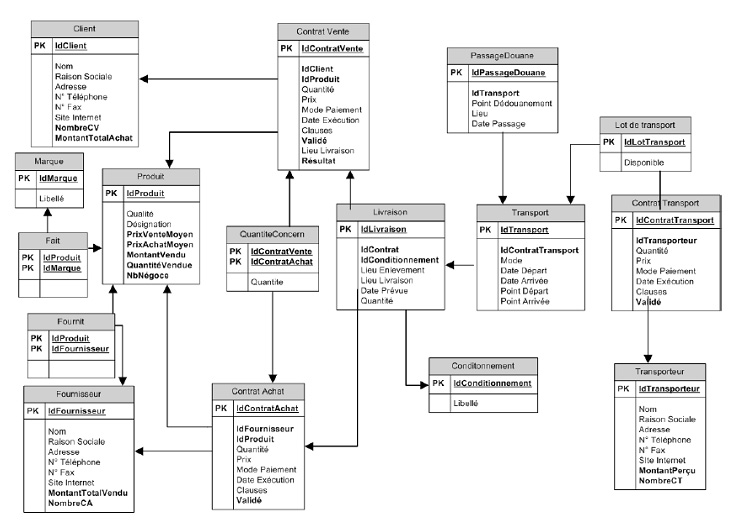
Le processus de gestion de laffrètement est illustré au travers un enchainement dactivités. On notera que ces activités nécessitent données et documents pour être exécutées le plus efficacement possible, ce qui implique une structuration robuste des informations nécessaires, une gestion rigoureuse et une répartition des responsabilités de mise à jour. A titre dexemple, pour négocier des contrats de transports, outre lintérêt de connaitre les données sur les transporteurs, les livraisons, les clients et fournisseurs, il est utile de connaître les règlements, les conventions et avoir accès aux informations juridiques nécessaires à une bonne négociation. Aussi, lors de lexécution de lactivité « choix/appel transporteur/négociation » (figure 5) qui permet, entre autre, de choisir le transporteur pour la négociation, lacteur de lentreprise doit-il disposer des moyens lui permettant de consulter toutes les ressources dinformation de son entreprise pour rechercher touts documents, informations ou autres types de données provenant de ces transporteurs les rendants indisponibles pour le transport. Ce contrôle peut augmenter la durée du cycle de vie du processus mais garantira la qualité du résultat de ce dernier et améliorera son efficacité. Nous nous appuyons sur lhypothèse quil est préférable de ralentir un processus pour garantir la qualité des résultats produits. Laccès se fait, généralement, par le biais dune multitude doutils. Labsence dun moteur de recherche permettant linterrogation simultanée des sources dinformations (serveur GED, serveur mail, serveur multimédias, serveur de données, etc.) amène lacteur de lentreprise à interroger plusieurs outils (tous les serveurs de lentreprise) séparément avant de réunir les informations répondant à la même requête, à savoir « y a-t-il eu des informations, non encore prises en compte par le système, qui peuvent modifier la liste-transport après son établissement par lactivité précédente? ». Du point de vue des acteurs de lentreprise, pour des raisons de gain de temps et damélioration de lefficacité des processus, il serait souhaitable de navoir quune seule interface permettant dinterroger plusieurs sources dinformation et de disposer, ainsi, dun outil fédérateur capable dinterroger simultanément toutes les sources de connaissances. Cet outil fédérateur met à la disposition de lacteur de lentreprise des documents et des données qui lui permettent de distinguer les documents et données utiles en fonction du contexte. Ce dernier pouvant être défini par rapport au client, fournisseur et transporteur. En effet, lacteur peut mener des négociations différentes selon quil sagit dun transporteur aérien ou routier, dun fournisseur de denrées biologiques ou de produits carnés, ou encore dun client local et un client international. Les différences dappréciations relèvent des contrats qui sont le plus souvent individualisés. La sous-section III-3 répond à ces questionnements en proposant une architecture de mémoire dentreprise orientée processus métier et sappuyant sur une approche hybride basée sur lingénierie des connaissances, lingénierie documentaire et la médiation sémantique et exploitant le référentiel processus comme ontologie de domaine. 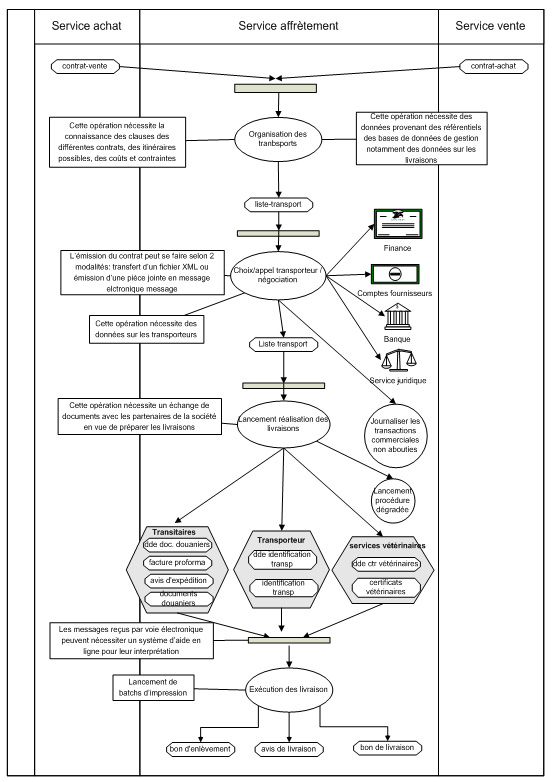
III-2. Architecture générale pour une mémoire dentreprise orientée-métierCausannel (Caussanel, 1999) distingue au travers des différents travaux qui ont été réalisés dans le domaine de la gestion des connaissances, lapproche orientée information de lapproche orientée connaissances. Selon lauteur, lapproche orientée information pour la gestion des connaissances se concentre sur lamélioration de la gestion et de léchange dinformations en essayant déviter les frontières organisationnelles ou professionnelles. Elle se fonde sur lélaboration doutils informatiques facilitant le travail coopératif et la communication entre les différents collaborateurs de lentreprise (ex : outils de groupware). Elle permet également léchange de connaissances explicites au moyen doutils de type workflow ou gestion documentaire. Lapproche orientée connaissances, très liée aux recherches effectuées en Ingénierie des Connaissances, se base sur une étape de capitalisation qui consiste à recenser puis à modéliser les connaissances (Abecker, 1998). Les connaissances sont alors modélisées (i.e. représentées sous forme dinformations) tout en intégrant une sémantique et un contexte pour former une Base de Connaissances. Lélaboration dun tel système correspond à une phase de capitalisation dun sous-ensemble ou de lensemble des connaissances de lorganisation. Cest dans la première approche que sinscrit notre contribution. Pour tenter une définition de la mémoire dentreprise sur le plan technique, nous dirons quune mémoire dentreprise est lensemble des outils permettant de rechercher et dexploiter lensemble des ressources de lorganisation ou de lentreprise en vue de reproduire des savoir-faire, de rendre efficace des processus, et de capitaliser les connaissances. Pour concevoir une telle mémoire dentreprise, il est important den définir une architecture. Celle que nous proposons ici vise à fournir linfrastructure modulaire nécessaire à lélaboration dun système de gestion des connaissances qui sinterface avec le SIE tout en sappuyant sur les techniques du Web sémantique et les standards des technologies de linformation et de la communication. Au sein de cette architecture (figure 6), trois niveaux sont distingués :
Cette architecture permet de mettre en uvre un processus dintégration (voir section IV) qui vise à aider un acteur dune entreprise dans la recherche dinformations utiles à lexécution des processus métier. Cette architecture nous permet donc denvisager un mémoire dentreprise orientée processus métier car elle peut être sollicitée à chaque exécution dune activité qui nécessite des données complexes provenant de sources hétérogènes. 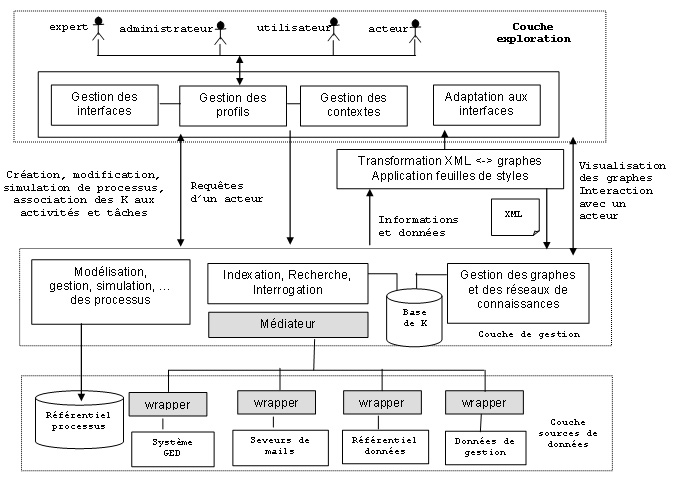
III.2.1. La couche explorationLexploration de la mémoire dentreprise comprend un nombre de services permettant à des acteurs différents de lentreprise daccéder à des informations pour optimiser les processus quils exécutent. Les services offerts par la couche exploration doivent donc être tournés vers les acteurs. Ils permettent la gestion des profiles, des contextes et des interfaces. On peut y trouver des fonctions dadaptation des interfaces aux contenus selon quil sagisse de pocket PC, de téléphone portable, etc. La gestion des profils permet de prendre en compte lorganisation des responsabilités des acteurs au sein de lentreprise. En effet la mémoire dentreprise doit sadapter à lacteur. Par exemple, un décideur a besoin de connaissances synthétiques, un acteur lambda a besoin de connaissances opérationnelles. La gestion du profil sappuie sur la description, le plus souvent hiérarchique des acteurs. La mémoire dentreprise doit également prendre en compte le contexte qui peut se déterminer par rapport à un ensemble de tâches effectuées par lacteur. Le contexte se définit alors par la trace dexploitation de la mémoire dentreprise dans un intervalle de temps. La combinaison du profil des acteurs et des contextes dutilisation permet daffiner les attentes des acteurs et de rendre pertinent les processus de recherche de linformation. Faciliter la mise en contexte de linformation est également un objectif de la couche dexploration car une information est dautant plus vite assimilée quelle est présentée dans un contexte proche de celui que lacteur connaît bien. III.2.2. La couche gestion de la mémoireLa couche de gestion de connaissances réutilisables est chargée de mettre à la disposition des utilisateurs, en particulier les experts du domaine, des fonctionnalités nécessaires à lintégration de nouvelles connaissances dans le système. Grâce à ces fonctionnalités lexpert doit pouvoir saisir les connaissances implicites selon le formalisme du référentiel des processus préalablement prédéfini et transformer ainsi les savoir-faire en une matière utilisable. Cela passe souvent par la mise en uvre dontologies de processus métier. Une solution pratique est ensuite de générer les éléments de connaissances introduits par lexpert, en documents XML selon des structures prédéfinies par les DTDs ou de schéma XML par exemple. Les principales fonctionnalités des modules de modélisation, de gestion, et de simulation des processus concernent :
L'indexation étant l'étape préparatoire pour la recherche dans la mémoire dentreprise, le module dindexation se connecte systématiquement à la base de connaissance via le module de traitement de requêtes. Le module de traitement des requêtes (médiateur) est responsable de fournir les résultats pertinents aux requêtes des utilisateurs de la mémoire dentreprise. Il est chargé danalyser et de traiter les requêtes exprimées par lutilisateur afin de construire des requêtes précises. Ces traitements reposent sur la base de connaissances, où le module permet linterrogation du schéma de lontologie à la fois pour lexplorer et pour sassurer de sa cohérence. Linterrogation de lontologie se caractérise donc par deux aspects importants :
III.2.3. La couche source dinformationLe principe de l'architecture du système à mettre en place consiste à autoriser un accès centralisé et structuré à des sources dinformation multiples et hétérogènes. Une des approches les plus usuelles est dutiliser la notion de « médiateur ». Dans cette approche, les données restent stockées et réparties au niveau des sources dinformation, ce qui est fort intéressant dans le cadre de la mise en place de mémoires dentreprise autour dun existant. Le médiateur joue alors le rôle dinterface entre lutilisateur et les sources dinformation en lui donnant limpression quil interroge un système centralisé et homogène. Les programmes à écrire doivent pouvoir permettre :
Lorsque l'on doit interroger différentes bases de données, plusieurs problèmes sont à prendre en compte dont les suivants :
Lorsqu'un utilisateur émet une requête vers une interface centrale, cette interface doit déterminer vers quelle(s) source(s) envoyer la requête, et doit aussi être capable de modifier la requête si nécessaire avant de l'envoyer à une source. Cette requête doit arriver au système gérant la source de données dans un langage compréhensible par ce système. Pour réaliser linterprétation aussi bien des requêtes que des résultats, il est nécessaire de disposer dun système capable de réaliser ces deux fonctions. On parle alors de « médiateur ». Un médiateur peut donc "dialoguer" avec plusieurs wrappers (qui, de plus, peuvent aussi être interrogé par différents médiateurs). Un wrapper sera en revanche dédié à une seule source de données.
III.3. Complémentarité entre lIngénierie documentaire et lIngénierie des connaissancesLa conception et la réalisation dune telle architecture se doit de combiner différentes approches et techniques. Les dimensions « document » et « connaissance » sont centrales dans une mémoire dentreprise et nécessite donc aussi bien lusage de techniques documentaires que de technique de gestion de connaissances. En effet :
Les techniques de lingénierie documentaire qui sappuient sur des langages de description SGML, XML, RDF, RDFS, etc. offrent un bon niveau dans lindexation, le stockage et la recherche dinformations. Par exemple, RDF permet dannoter des documents avec un formalisme permettant de faire référence à des connaissances terminologiques sous formes dontologies. De cette manière, une requête de recherche dinformation peut faire lobjet de raisonnements élémentaires reposant sur les connaissances modélisées. XML étant amené à jouer le rôle de standard international pour les documents structurés, cela permet dassurer la pérennité des documents et des informations à long terme, dans le cadre de la mémoire dentreprise. Cela ménage la possibilité de migrer vers de nouveaux outils de gestion documentaire en conservant le patrimoine dinformation. IV. Processus dintégrationDans notre architecture, les couches interagissent entre elles. Le principe repose sur la notion de services ; aussi la couche n sappuie t-elle les services de la couche n+1. Cest ainsi que la couche exploration sollicite la couche de gestion pour pouvoir répondre aux acteurs sur des besoins de dinterrogation, de recherche, de modélisation, dindexation, etc. La couche de gestion sollicite la couche de données pour des besoins de restitution de connaissances issues de différents serveurs (données, GED, serveur de mails, ), mais aussi des besoins de stockage et daccès au données. Sur la figure 6, on note, en guise dillustration, que la couche exploration peut solliciter la couche de gestion pour assurer toutes les tâches liées à la manipulation des processus (création, stockage dans le référentiel, etc.). La couche exploration peut solliciter la couche de gestion pour interroger la mémoire dentreprise en termes de connaissances (sur la figure 6, le message correspondant à la requête dun acteur illustre ce fait). On notera quune bonne partie des échanges entre les couches doit se faire à travers lutilisation de XML pour assurer la pérennité nécessaire à ce type de mémoire. Le principe de fonctionnement et darticulation des couches, illustré par la figure 7, se fait selon un certain nombre détapes qui organise en séquence des processus décrits en section IV.2. IV.1. Liste des processus dintégration des sources hétérogènesProcessus de formulation : ce processus est déclenché par un acteur externe. Dans ce processus :
Processus de transformation : ce processus se charge de construire des requêtes suite aux exigences de lacteur. Il se base notamment sur la transformation de demandes des acteurs sous une forme compréhensible par la « couche de gestion ». Il soumet la requête au médiateur. Processus de médiation : ce processus se déroule selon les étapes suivantes :
Processus dextraction : à travers les wrappers, les services dexécution des requêtes (mails, GED, référentiels données, données de gestion) interrogent respectivement les documents XML correspondants dans la « couche source de données » ; les résultats des interrogations sont stockés respectivement dans :
Processus de restitution : cest le processus qui est exécuté en fin de séquence en ordonnant les étapes suivantes :
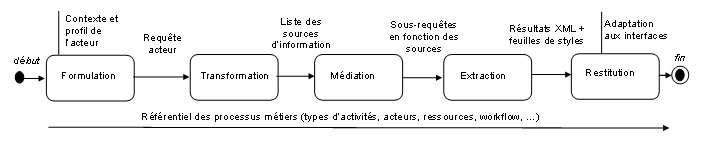
Il est à noter quune tâche récurrente est exécutée par le système indépendamment des accès explicites des utilisateurs. Cette étape permet dindexer toute nouvelle source dinformation et alimenter la base de connaissances. Lindexation est une tâche cruciale qui nécessite des experts du domaine pour le choix des termes du corpus à indexer. Dans notre solution, le système dindexation permet en outre détablir des liens entre sources hétérogènes dans le cadre de processus métier clairement définis en termes dactivités, dacteurs et de ressources. IV.2. Illustration : aide à la négociation de contratsLors du processus daffrètement dune entreprise de négoce international présenté dans la section III.1, un acteur est amené, lors de la négociation de contrats avec des transporteurs, à solliciter des informations pouvant provenir des bases de données et des référentiels, des messageries et du système documentaire. La première source va permettre à lacteur daccéder à des informations factuelles des clients, des fournisseurs et des transporteurs telles que ses coordonnées mais aussi leurs chiffres daffaire. La deuxième source permet à lacteur daccéder à une information qui lui fournit des connaissances sur les échanges quil a eus avec ces partenaires avant la négociation. La troisième source dinformation lui permettra davoir une sorte de best-practise sur la gestion de contrats puisquil peut avoir accès soit aux derniers contrats quil a négociés avec ces partenaires mais aussi des guides de négociation de contrats similaires. Plus précisément, lors de son activité de « choix de transporteur », un acteur du département « Affrètement » déroule un scénario qui sappuie sur un algorithme visant à choisir le « meilleur » transporteur, en termes de coût, pour assurer des livraisons dun point à un autre tout en respectant les délais. Pour cela, il contacte chacun des transporteurs dune liste préalable et négocie avec chacun deux. Il sappuie pour cela sur les informations suivantes :
Une fois le transporteur sélectionné comme étant celui qui répond le mieux aux critères et contraintes de coûts, de délais et de fiabilité, un contrat de transport est élaboré et signé. Les données sur les clients, fournisseurs et livraisons y sont consignés. Le guide de rédaction des contrats permet à lacteur de négocier les différentes clauses du contrat. Dans un tel scénario, on peut imaginer que lacteur formule la requête : « retrouvez toute linformation utile pour négocier un contrat de transport avec tels clients et tels fournisseurs ». La mémoire dentreprise doit permettre de restituer, sous forme lisible, les informations nécessaires. Pour cela, elle sappuie sur le type dactivité que lacteur est entrain dexécuter, en explorant le référentiel des processus métier de la mémoire dentreprise pour établir les liens entre informations. La mise en uvre du mécanisme de fonctionnement de larchitecture que nous proposons pour cet exemple est illustrée par le tableau Tab 1.
V. Conclusion et discussions
Lenjeu de toute entreprise est datteindre ses objectifs planifiés dans sa stratégie globale. Nous avons montré que pour atteindre les objectifs de lentreprise, les acteurs doivent prendre les bonnes décisions lors de lexécution des processus métiers et lamélioration, en continue, des performances de ces derniers, nécessite lexploitation des mémoires dentreprise dont il faudra définir larchitecture. Concernant larchitecture dune mémoire dentreprise, lingénierie documentaire peut fournir un levier pour la concrétisation de la mise en uvre de la mémoire dentreprise. Ainsi, lindexation documentaire peut-elle se révéler particulièrement intéressante dans le contexte dune mémoire dentreprise. Lingénierie documentaire peut également être exploitée, pour la formalisation des savoir-faire dexperts. Ceci consiste à transcrire les connaissances sous une forme exploitable et échangeable entre les individus mais aussi, entre des applications hétérogènes. Lutilisation dXML comme support de formalisation et dexplicitation des savoir-faire offre lavantage de structurer les connaissances selon des balises. Ces dernières sont fournies par les métadonnées et les concepts préalablement créés à partir de lontologie. BibliographieABECKER A., BERNARDI A., HINKELMANN K., KUHN O., et SINTEK M. (1998). Toward a technology for organizational memories. IEEE Intelligent Systems, May/June. http://citeseer.nj.nec.com/abecker98toward.html BACHIMONT B. Pourquoi ny a-t-il pas dexperience en ingénierie des connaissances ? In Actes de la conférence (Ingénierie des connaissances IC2004), N. MATTA (ed), Lyon. Presses Universitaires de Grenoble. BLASIUS K.H., HEDSTUCK U., ROLLINGER C-R. (1989). Sorts and Types in Artificial Intelligence, volume 418 of Lecture Notes in Artificial Intelligence. Springer Verlag, Berlin. 307 p. BRACHMAN R. (1977). A Structural Paradigm for Representing Knwoledge. Thèese : Harvard University, USA,. CAUSSANEL J., CHOURAQUI E. (1999). Information et Connaissances : quelles implications pour les projets de Capitalisation des Connaissances, in: Revue Document numérique - Gestion des documents et Gestion des connaissances, vol. 3-4, pp. 101-119. CHARLET, J. (2002). Lingénierie des connaissances : développement, résultats et perspectives pour la gestion des connaissances médicales. HDR. Paris : Université Pierre et Marie Curie, 142p CHEIN Michel et MUGNIER Marie-Laure (1992). Conceptual Graphs : Fundamental Notions. Revue dIntelligence Artificielle, vol 6, n°4, p. 365-406. DAVIS, R., SHROBE, H., SZOLOVITS, P., (1993). What Is a Knowledge Representation ? AI Magazine, vol 14, n°1, p 17-33. DIENG, R., CORBY O., GANDON F., GIBOIN A., GOLEBIOWSKA J., MATTA N., RIBIERE M. (2005). Knowledge Management: Méthodes et outils pour la gestion des connaissances. 3ème éd. Paris, Dunod. P 450. ISBN 2 10 049635 2 LEBRATY J.F, (2000). Les systèmes décisionnels, Encyclopédie des systèmes d'information, Vuibert. Le MAITRE J., MURISASCO E., BRUNO E. (2004). Recherche dinformations sur les documents XML, In : Méthodes avancées pour les systèmes de recherche dinformations, Traité STI, Hermès, pp. 35-44, M.Ihadjadene. MINSKY, M. (1975). A Framework for Representing Knowledge. The Psychology of Computer Vision. Edited by Winston P.H., p 245262. McGraw-Hill, New York. MORLEY C., HUGUES J., LEBLANC B., HUGIES O. (2005). Processus métiers et S.I: Evaluation, modélisation, mise en uvre. Paris, Dunod. P 237. ISBN 2 10 007099 1 MUGNIER M-L, CHEIN M. (1996). Représenter des connaissances et raisonner avec des graphes. Revue dintelligence artificielle, vol 10, n°1, p 7-56. NONAKA I., TAKEUCHI H. (1995). The Knowledge-Creating Company: How Japanese Companies Create the Dynamics of Innovation. Oxford University Press, 304 p. PARENT R., BOULET N. (1998). Rôle des professionnels et lingénierie documentaire. Rapport issu de la journée de réflexion portant sur les rôles professionnels et lingénierie documentaire. Quebec, (www.services.gouv.qc.ac/fr/publications/enligne/administration/ingenierie/role_prof.pdf). QUILIAN M. (1968). Semantic Memory. Semantic Information Processing, pp 227270. MIT Press, Cambridge,MA, US. SOWA J.F. (1984). Conceptual Structures : Information Processing in Mind and Machine. The system programming series. Addison-Wesley. 481 p. |
| © Ressi, no.7, avril 2008, ISSN 1661-1802 |
| Date de dernière mise à jour : 30.04.2007 |