


Lors de ce séminaire, ce sujet passionnant très difficile à vulgariser a été brillamment présenté: entre les exemples pratiques, les schémas et les explications très pédagogiques des concepts sous-jacents, la salle est repartie avec quelques neurones supplémentaires. Mais d’ailleurs, pourquoi les neurones ? Qu’ont-ils à voir avec le machine learning et pourquoi nous parlent-ils ? C’est à mon tour de vous le retranscrire, en quelques mots…
Les réseaux de neurones ne sont pas trouvables que dans les cerveaux biologiques : ce sont aussi le nom de fonctions mathématiques, qui sont capables prendre un input (ou donnée d’entrée), de le transformer, et de produire un output (ou donnée de sortie). Plus il y a de couches et de neurones, plus les données peuvent devenir complexes! D’ailleurs, lorsqu’on parle de couches multiples, on parle de couches intermédiaires, aussi appelées couches cachées ou hidden units.
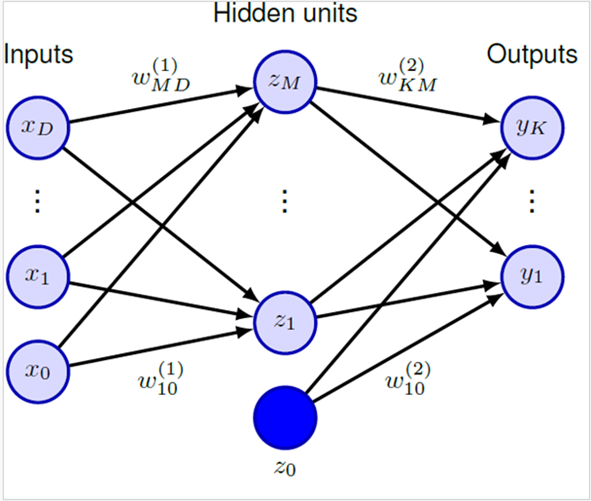
Mais à quoi cela sert-il ? Et bien à beaucoup de choses ! Les réseaux de neurones peuvent être appliqués à des tâches très complexes, et sont utilisées dans les applications de reconnaissance faciale, dans les voitures autonomes, le traitement du langage naturel, les traducteurs automatiques, ou même dans la détection de fraude. Il en faut des neurones pour faire tout cela…
Ce qui nous intéresse ici, c’est la partie du langage : un sujet brûlant depuis quelques années, avec ChatGPT et la démocratisation de ce genre d’IA générative. Elles sont construites sur des grands modèles de langage, ou en anglais large language models. On les abrége par LLM et, tels des agents secrets, ils ont une mission : c’est d’apprendre les structures du langage, les liens entre les mots, le contexte de leur utilisation. Pour cela ils ont besoin de modèles de Transformers. Mais pas ici question de voitures-aliens-robots, n’en déplaisent aux fans : on parle ici d’un modèle de réseaux de neurones très puissant, qui a révolutionné les LLM par sa grande capacité.
En fait, l’ancêtre des transformers, c’était un peu les RNN, ou Recurrent Neural Network. Mais si, vous les connaissez ! Les auto-compléteurs, lorsque vous écrivez en e-mail, ou un SMS. Peut-être avez-vous déjà joué un peu avec cette fonction, en essayant de sélectionner tous les mots qu’il vous propose et former une phrase faite toute entière d’auto-compléteur ? Pour s’amuser un peu, j’ai décidé de le faire, en commençant par les mots “Advanced Neural Net”. Voici ce que l’auto-compléteur a proposé :
“Advanced neural net worth of the same as the other one I think I was in the same place as a team leader and they were the same as the other one who said it was a good idea to do it and I don’t know what to do with the kids and I don’t know what to do with the kids and I don’t know what to do with the kids.”
Un blocage légèrement sinistre sur la dernière phrase mis à part, qu’observe-t-on ici ? Eh bien, pas une phrase cohérente en tout cas! Cela est dû à la façon dont les RNN fonctionnent. Ils prennent en compte les éléments précédents (donc les mots entrés précédemment) de façon séquentielle. Cela pose des problèmes techniques qu’on appelle problèmes de “vanishing” et “exploding gradient”. En d’autres termes, ils sont limités !
On a aussi développé d’autres outils, comme les LSTM ou les GRU, mais il avaient d’autres problèmes, car soit trop gourmand en puissance de calcul, soit en mémoire ! Les transformer sont plus performants et permettent une parallélisation, ce qui change tout notre paradigme.
Dans l’article “Attention is all you need” (Vaswani & Co, 2017), présenté en premier dans ce séminaire, les auteurs ont utilisé en premier le concept du mécanisme d’attention (exemple des « livre ») : comment la machine peut comprendre le contexte pour interpréter les mots. La solution technique, c’est de comparer la Query avec toutes les keys (éléments/mots) pour déterminer les associations les plus pertinentes : c’est le mécanisme d’attention. Ils ont ainsi démontré que leur grand modèle a fait bien mieux en performance que les autres (métrique BLEU).

Dans le second article, “From ChatGPT to CatGPT : The Implications of Artificial Intelligence on Library Cataloging” (Brzustowicz, 2023), l’auteur a demandé à ChatGPT de générer des notices de catalogage de bibliothèque. On relèvera que l’auteur n’a pas partagé les requêtes qu’il a entrées, ce qui serait souhaitable dans ce genre de démarche. Sa conclusion, après avoir généré diverses notices – une qui n’avait encore aucune entrée dans WorldCat par exemple, c’est que le potentiel de l’IA est prometteur pour le futur du catalogage. Cependant, une intervention humaine reste importante, car ChatGPT a régulièrement fait des erreurs, des répétitions, des imprécisions. Il a également inventé lorsqu’il ne trouvait pas d’information, ce qui prouve qu’il ne devrait être utilisé que comme moyen auxiliaire pour le moment.
L’article RLHF Deciphered: A Critical Analysis Of Reinforcement Learning From Human Feedback For LLMs (Chaudhari et al., 2024) présenté en dernier nous parle du concept de RLHF : L’apprentissage par renforcement à partir du feedback humain. C’est une technique pour améliorer les LLMS, en alignant leurs réponses sur les préférences humaines. En effet et comme vu précédemment, les LLMs peuvent halluciner, c’est à dire donner des informations qui semblent crédibles mais qui sont fausses ou absurdes. De plus, ils peuvent être fortement influencés par des biais humains non voulus, et donner des réponses problématiques, dites aussi “toxiques”. 3 principes de base sous-tendent cette démarche d’alignement : Helpfulness, Honesty, Harmlessness.
La méthode RLHF est un processus itératif qui prend en compte un feedback humain sur les réponses du LLM, et ce qu’on appelle un système de récompenses. Ces récompenses sont en fait un score, qui va être utilisé pour aider le LLM a donné des réponses souhaitables en essayant de maximiser ce score. Les avantages du RLHF sont nombreux : amélioration de la qualité des réponses, réduction des biais, adaptation aux contextes culturels et éthiques, amélioration et donc renforcement de la confiance des utilisateurs. Mais il présente aussi des limitations, en particulier des problèmes de calibration dans le cas où les données d’entraînement seraient très différentes de celles entrées ensuite. Une forme de subjectivité et de fragilité est également impossible à éviter, du fait justement de ce feedback humain.
En conclusion, les “Advanced Neural Net” sont une nouvelle technologie cruciale, qui n’a pas fini de nous étonner, mais il faut garder un esprit critique : car même si les LLM sont extrêmement puissants, ils sont aussi très complexes et peuvent avoir des biais, puisqu’ils sont en quelque sorte notre miroir. En effet, afin de mieux nous servir, ils doivent être faits à notre image : entraînés sur nous, par nous, pour nous. Et comme on le sait, “Errare humanum est” !
Laisser un commentaire