

Pauline est responsable marketing dans une entreprise de commerce en ligne. Chaque jour, elle analyse des milliers de données : comportements d’achat, tendances des produits, historique des clients… Avec la croissance de l’entreprise, cela devient un défi. Plus elle essaie de tout gérer, plus elle se rend compte qu’elle manque de temps et que les décisions basées uniquement sur son intuition ne sont plus suffisantes.
Un jour, Pauline assiste à une conférence sur le Machine Learning, une technologie qui permet aux machines d’apprendre des données et de prendre des décisions sans avoir à tout programmer. Intriguée, Pauline décide de mettre cette technologie à l’épreuve dans son entreprise.
Elle déploie un modèle de Machine Learning supervisé pour analyser les comportements d’achat de ses clients. Ce modèle utilise des données historiques, comme le nombre d’achats passés, le panier moyen ou encore la fréquence de visite de son site de commerce. Le modèle apprend des données passées pour faire des prédictions précises.
L’apprentissage supervisé : Quand on sait déjà ce qu’on cherche
Dans l’apprentissage supervisé, le modèle est entraîné avec des données pour lesquelles la réponse est déjà connue. Par exemple, en marketing, cela peut consister à prédire si un client va acheter un produit en fonction de son historique d’achat passé. Le modèle apprend des exemples (données étiquetées) et utilise ces connaissances pour prédire des événements futurs.
| ID Client | Âge | Nombre d’achats passés | Panier moyen (CHF) | Fréquence de visite par mois | A acheté le produit ? |
|---|---|---|---|---|---|
| 1 | 25 | 3 | 50 | 5 | Oui |
| 2 | 40 | 10 | 100 | 15 | Non |
| 3 | 35 | 7 | 75 | 8 | Oui |
| 4 | 22 | 2 | 40 | 4 | Non |
| 5 | 30 | 5 | 60 | 6 | Oui |
| 6 | 50 | 12 | 120 | 20 | Non |
| 7 | 28 | 6 | 80 | 9 | Non |
| 8 | 60 | 1 | 30 | 3 | Non |
Dans le jeu de données précédent, on cherche à prédire “A acheté le produit ?”. C’est la variable que l’on appelle souvent “target” ou “variable cible”. Pour prédire cette “variable cible”, on utilise les autres colonnes qui vont nous aider à repérer des relations entre elles et la “target”.
Pauline utilise aussi un modèle non supervisé pour segmenter ses clients en groupes. Elle n’a pas besoin de lui dire quels groupes existent ; le modèle analyse simplement les données (comme les comportements d’achat ou les préférences) et découvre des patterns cachés, comme des clients ayant des comportements similaires. Ce type de modèle permet de mieux cibler les campagnes marketing en fonction des segments découverts.
L’apprentissage non supervisé : Découvrir des structures sans réponse préalable
L’apprentissage non supervisé, quant à lui, est utilisé lorsqu’il n’y a pas de réponse prédéfinie. Le modèle cherche à découvrir des structures ou des relations dans les données. Par exemple, il pourrait regrouper des clients ayant des comportements similaires sans qu’on lui dise au préalable ce qu’il doit chercher.
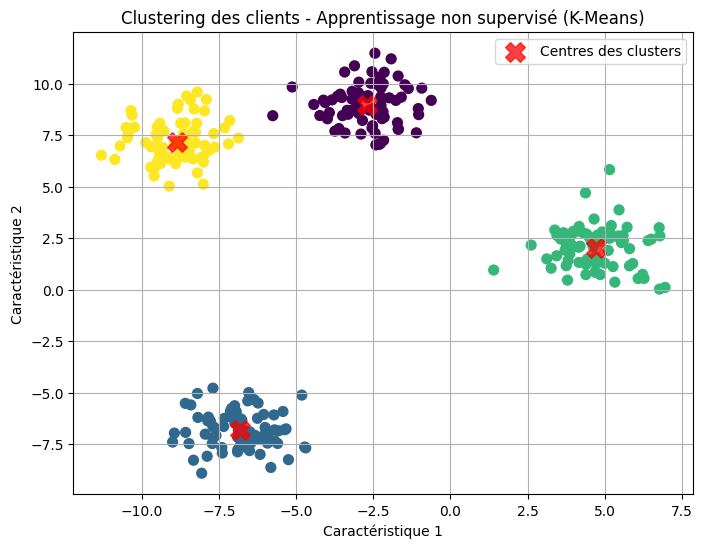
L’image ci-dessus représente le groupement de clients effectué par Pauline en utilisant un modèle non-supervisé.
Cependant, comment ces modèles fonctionnent-ils réellement ?
Modèles paramétriques vs non paramétriques
Tous les modèles de Machine Learning n’utilisent pas la même approche. Certains sont paramétriques, d’autres sont non paramétriques.
Modèles paramétriques
Ces modèles fonctionnent souvent sur des hypothèses concernant la structure des données. Par exemple, dans la régression linéaire, on suppose qu’il existe une relation simple et droite entre les différentes variables. Ce modèle utilise un nombre limité de paramètres pour faire des prédictions. C’est rapide et efficace pour des problèmes simples, mais ça peut devenir un peu limité si les données sont plus complexes ou ont des relations moins évidentes.
Prenons un exemple concret avec une boîte qui analyse des images de chats et de fraises. On lui envoie une image de fraise, mais au départ, la boîte a encore ses réglages de base. Elle regarde l’image et se trompe en pensant que c’est un chat. Pas de souci, elle va ajuster ses paramètres pour mieux comprendre et corriger son erreur. Elle recommence ce processus avec chaque nouvelle image qu’on lui montre, apprenant petit à petit les patterns (les caractéristiques spécifiques) des fraises et des chats.
Une fois qu’elle a vu assez d’exemples, la boîte ne dépend plus des images exactes qu’on lui a montrées pendant l’entraînement. Elle a appris les caractéristiques communes des chats et des fraises et peut donc identifier une nouvelle image correctement, même si elle ne l’a jamais vue auparavant.
Modèles non paramétriques
Contrairement aux modèles paramétriques, les modèles non paramétriques ne font aucune hypothèse sur la forme des données. Ils sont donc beaucoup plus flexibles et peuvent s’adapter à des structures beaucoup plus complexes. Par exemple, l’algorithme des k plus proches voisins (k-NN) ne suppose pas de relation prédéfinie entre les différentes variables. Au lieu de cela, le modèle regarde les données “telles quelles” et prédit directement à partir des données stockées les plus semblables.
Cela signifie qu’un modèle non paramétrique est directement dépendant des données. Plus il reçoit d’exemples, plus il devient précis, mais il doit conserver toutes ces données en mémoire pour faire ses prédictions. Cela peut le rendre plus lent, car il n’essaie pas de généraliser à partir d’une simple formule, mais il apprend à partir de chaque point de données individuellement.
En d’autres termes, au lieu de chercher une relation simple et prédéfinie (comme dans la régression linéaire), le modèle s’appuie sur les données elles-mêmes pour trouver des patterns et faire des prédictions. Il compare les nouvelles données avec celles qu’il a déjà vues et cherche les points les plus proches dans l’espace des données.
L’importance du Machine Learning
Grâce au Machine Learning, Pauline peut prendre des décisions plus éclairées, sans avoir à analyser chaque détail manuellement. Elle gagne du temps, et surtout, elle peut mieux comprendre ses clients, en détectant des tendances cachées qu’elle n’aurait jamais pu repérer seule.
Au fil des mois, son modèle devient plus intelligent, s’améliorant constamment à mesure que de nouvelles données sont ajoutées. Pauline n’a plus à deviner ce que ses clients veulent. Son assistant virtuel le sait déjà.
Conclusion
Le Machine Learning est bien plus qu’une simple tendance technologique ; c’est un changement de paradigme dans la manière dont les entreprises prennent des décisions. À travers des modèles supervisés et non supervisés, paramétriques et non paramétriques, cette technologie permet d’exploiter les données pour prédire, segmenter, et optimiser des actions de manière bien plus efficace qu’auparavant.
Dans l’exemple de Pauline, nous voyons comment ces modèles peuvent être appliqués concrètement pour prendre des décisions marketing plus pertinentes et personnalisées. Et ce n’est qu’un début. Le Machine Learning a encore un long chemin à parcourir et de nombreuses opportunités à offrir.
Pour aller plus loin…
Je vous conseille fortement de regarder cette vidéo de la chaîne YouTube “Artificialis Code” qui explique très bien les concepts de classifications et de régressions. Cela permet de développer vos connaissances en la matière !
Bibliographie
Data Mining: Practical Machine Learning Tools and Techniques, 2011. Elsevier. ISBN 978-0-12-374856-0.
KOH, Dow-Mu et al., 2022. Artificial intelligence and machine learning in cancer imaging. Communications Medicine. Vol. 2, no 1, p. 133. DOI 10.1038/s43856-022-00199-0.
CGP Grey, 2017, How AIs, like ChatGPT, Learn [en ligne]. Disponible à l’adresse : https://www.youtube.com/watch?v=R9OHn5ZF4Uo&list=WL&index=15 [Consulté le 14 novembre 2024].
Artificialis Code, 2024. Modèles paramétriques vs Non-paramétriques (MLMC #0.4) [en ligne]. Disponible à l’adresse : https://www.youtube.com/watch?v=cq2LeFlgJXU [Consulté le 25 novembre 2024].
Tanoraa, 2024. Post sur le K-Means Clustering. Disponible à l’adresse : https://fr.linkedin.com/posts/tanoraa_k-means-clustering-comment-lia-segmente-activity-7244994195650695169-PqaP [Consulté le 25 novembre 2024].
Laisser un commentaire