

Lors de notre billet de blog précédent, nous vous avions présenté le contexte du projet et des données utilisées pour celui-ci. Il vous est donc fortement recommandé de le lire pour bien comprendre les données que nous traitons dans le cadre de notre projet.
Afin d’être en mesure de classifier les différentes pathologies de la démarche, il est important d’avoir bien pris connaissance des données que nous allons traiter, car il s’agit du domaine dans lequel on souhaite spécialiser notre modèle d’apprentissage automatique.
L’apprentissage automatique
Le « machine learning » est le domaine scientifique qui étudie le développement d’algorithmes capables d’extraire des modèles depuis des données à des fins de prise de décision, par exemple.
Un modèle statistique peut être vu comme une suite de règles qui permettent de classifier un sujet, dans notre cas, un patient. Au lieu de devoir formaliser ces règles manuellement, on demande à la machine de les créer en s’entraînant sur les données fournies.
« Garbage in, garbage out »
Le contrôle approximatiflors de la récolte des données peut faire ressortir des incohérences (e.g. une longueur de jambe en degrés), des combinaisons impossibles (e.g. homme et enceinte), des valeurs manquantes, etc.
Faire usage de données non filtrées peut causer des problèmes d’interprétation et des résultats erronés peuvent en découler. Il est donc impératif de n’utiliser que les données « nettoyées » afin de faciliter l’apprentissage des modèles. Ce processus est appelé « preprocessing ».
Le « preprocessing » effectué varie en fonction des méthodes d’apprentissage choisies, à savoir les arbres décisionnels, les réseaux de neurones convolutifs et récurrents, dans le cadre de notre projet. Voici les critères de filtrage et transformations sur les données que nous avons choisis :
Arbres décisionnels :
- Aucune donnée manquante
- Convertir les données continues en données catégoriques
Réseaux de neurones:
- Aucune donnée manquante
- Convertir les données catégoriques en données numériques
- Mettre à la même échelle les données
Une fois les données assainies, il est possible de les passer à une des méthodes d’apprentissage suivantes afin de tenter de mettre en évidence les corrélations existantes entre deux ou plusieurs paramètres et d’en prédire les différentes implications.
Random Forests – Forêts d’arbres décisionnels
Les arbres décisionnels font partie des méthodes d’apprentissage supervisé des plus simples. La classification se fait à travers la construction d’un arbre dont chaque nœud correspond à une condition sur l’un des attributs du patient, nous permettant de mieux déterminer la valeur à prédire. Chacun des nœuds est connecté à deux ou plusieurs branches. Chaque feuille correspond à une classification ou une décision prise par le modèle.
Cette structure arborescente rend la lecture et la compréhension du modèle possible par un être humain, contrairement aux autres méthodes de classification. De par ce fait, nous nous en servirons comme modèle de référence.
Les forêts d’arbres décisionnels, comme son nom l’implique, constitue un ensemble d’arbres décisionnels qui se différencient les uns des autres par leur sous-échantillonnage aléatoire sur les données initiales.
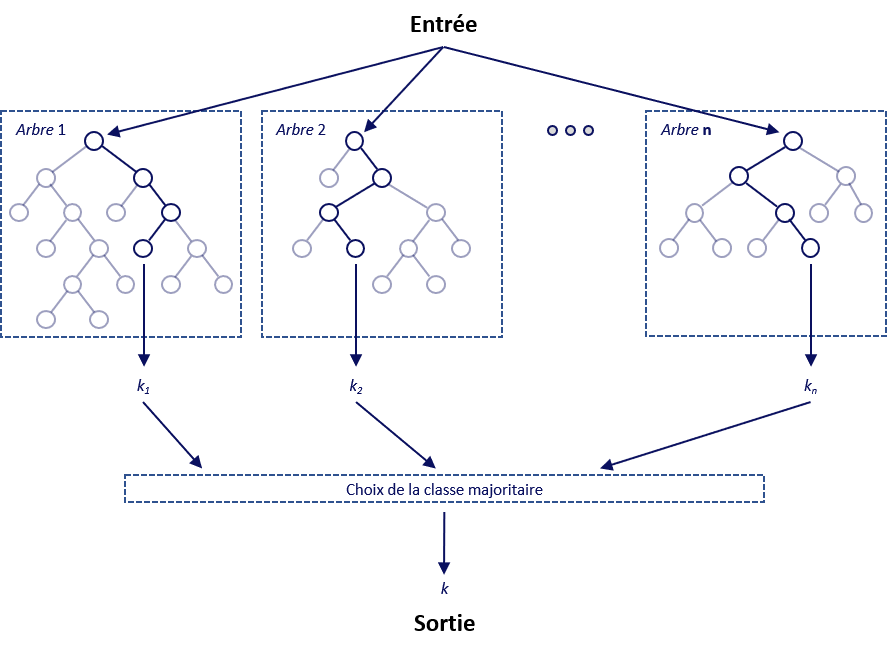
La décision prise par chaque arbre est ensuite représentée par un « vote » et la classe ayant accumulé le plus de votes servira de prédiction pour notre modèle.
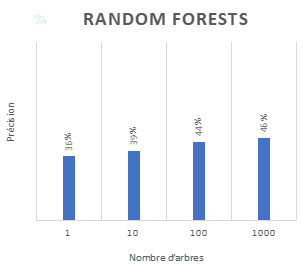
Dans le cadre du projet de recherche nous avons comparé les résultats avec 1, 10, 100 et 1000 arbres pour ne constater qu’une légère amélioration au niveau de la précision des résultats. Nous n’avons pas testé d’autres paramètres.
Convolutional Neural Networks – CNN
Un réseau de neurones à convolution, de l’anglais « Convolutional Neural Network » est une architecture spécialisée dans la reconnaissance d’images. Les graphiques générés par les capteurs placés sur le patient sont directement transmis au CNN en tant qu’image.
L’architecture de ce réseau se départage en une première partie appelée convolutive et en une seconde nommée classification.
Il existe 4 types de couches pour les réseaux de neurones convolutifs :
- Couche de convolution : Application d’un filtre sur l’image
- Couche de pooling : Compresser progressivement la taille de l’image intermédiaire
- Couche entièrement connectée : Dernière couche du réseau, permet de finalement classifier les données

Les différentes architectures de CNN comparées dans le cadre du travail de recherche :
- 3 Couches avec régularisation : 2 couches de convolution + pooling et 1 couche entièrement connectée + Dropout + BatchNorm
- 3 Couches : 2 couches de convolution + pooling et 1 couche entièrement connectée
- 2 Couches : 1 couche de convolution + pooling et 1 couche entièrement connectée
La régularisation permet l’apprentissage de modèles plus simples, évitant ainsi que ceux-ci ne soient trop dépendants des jeux de données.
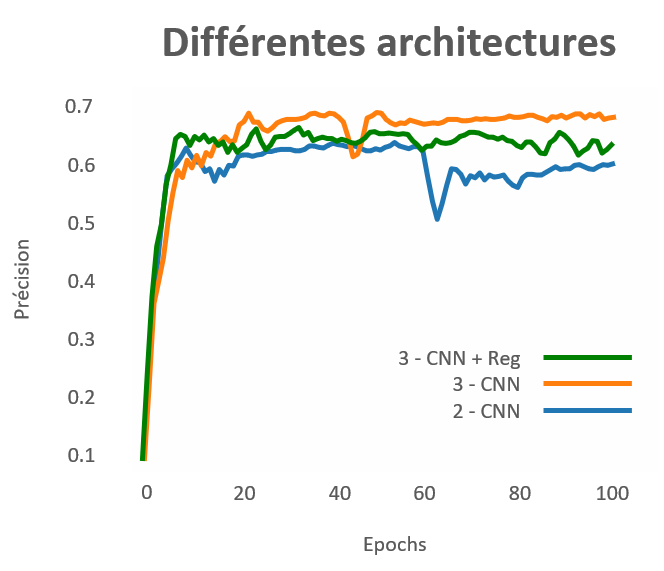
L’axe des ordonnées ici représente le nombre d’entraînements que chaque architecture a effectué. Chacune d’entre elle s’est donc entraînée 100 fois sur le jeu de données. Avec plus de 70% de précision, le modèle à 3 couches s’avère être le modèle le plus performant pour les CNN.
Recurrent Neural Network – RNN
Ce type de modèle, spécialisé dans le traitement des informations temporelles, semble être le choix idéal pour attaquer le problème auquel nous sommes confrontés. La démarche d’un patient pouvant être considérée comme une suite d’actions se déroulant dans le temps, ce modèle est donc conçu précisément pour ce genre de problème et doit en être la clé.
La force des RNN réside dans leur capacité à prendre en compte les informations des entrées des occurrences précédentes, traitant ainsi l’information plusieurs fois en la renvoyant chaque fois au sein du réseau.
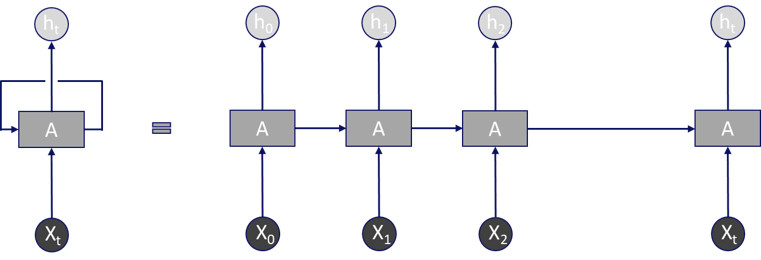
Il est important de noter que cette représentation semble montrer des unités qui se succèdent mais en réalité il s’agit de la même unité à différentes temporalités.
Voici les différentes variantes du RNN comparées dans le cadre du travail de recherche :
- RNN standard expliqué ci-dessus
- LSTM : RNN standard + Cellule de « Mémoire » permettant de maintenir l’information plus longtemps
- GRU : Structure similaire au LSTM mais simplifié
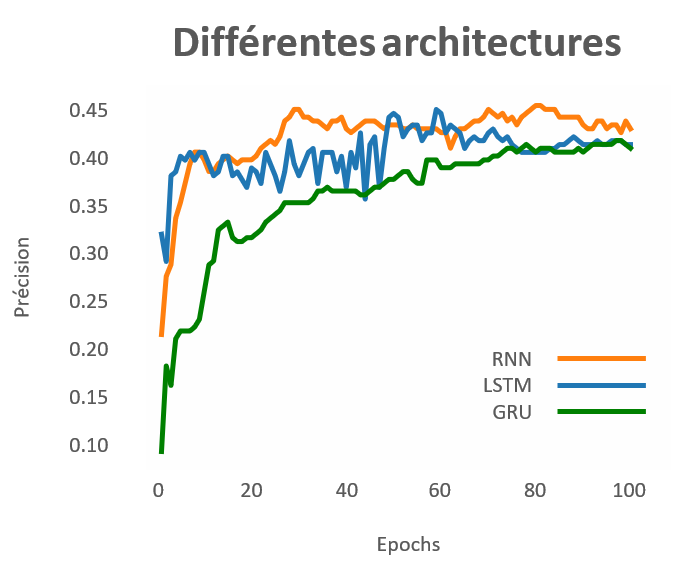
Les résultats tant attendus s’avèrent être un peu décevants et étonnement plus bas que les réseaux de convolutions avec une baisse de près de 30% de précision.
Améliorations possibles
Les résultats finaux n’étant pas aussi performants qu’attendus et en particulier pour les RNN, nous avons déjà pensé à quelques pistes d’amélioration :
- Réduction du nombre d’attributs utilisés
- Générer des données supplémentaires
- Aligner les marqueurs
Les données que nous avions à notre disposition étaient en très faible quantité (environ 1’000 démarches de patients) pour utiliser des techniques de « Machine Learning » et se trouvaient être assez complexes. En effet, chaque démarche de patient était générée par 20 capteurs sur 3 axes (3 dimensions) durant le temps que le patient mettait à parcours 10 m. Ce qui peut atteindre plus de 30’000 données pour une seule démarche de 5 secondes (20x3x500) et qui rend donc d’autant plus difficile à comprendre pour un modèle étant donné qu’il a très peu d’exemples. Ainsi, une amélioration possible serait de ne prendre en compte seulement un seul axe parmi les trois pour ne fournir au modèle qu’une représentation moins complexe des données.
Enfin, il serait judicieux d’aligner les marqueurs de chaque démarche pour que chacune d’entre elles commence au même moment et avec le même pied pour que celles-ci soient plus faciles à comprendre par nos modèles.
Laisser un commentaire