Il était une fois, il y a bien longtemps de cela, un pays imaginaire où les hautes écoles ne s’honoraient guère des larges talents pédagogiques dont s’enorgueillit aujourd’hui notre institution. Nous t’y transportons comme par magie, dans un cours de Neural Advanced Network. Pour tromper l’ennui, tu entreprends de chuchoter un conte des 1001 Nuits à la dernière de tes petits camarades de la rangée du fond, Tinou. Entre vous, trois copains que nous appellerons, par convenance, Olivier, Sophie et Alexandra.
Et tu commences…
Il était une
fois – derechef – dans une cité mythique du monde arabo-musulman, un jeune
homme pauvre qui avait aperçu la fille du roi et en était tombé amoureux…
Et la voix du
savoir de marteler, sans répit : « Le deep learning, consiste
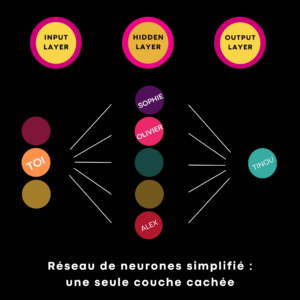
à apprendre à un réseau de neurones artificiels à faire des prédictions. Le
réseau, multicouche, comporte les neurones d’entrée avec les données
d’apprentissage (input), les couches cachées (l’espace latent où
les neurones décomposent les informations en caractéristiques) et la sortie (output). »
Toujours aussi soporifique ? Viens. Nous allons enseigner les
contes des 1001 Nuits à la Machine. En input, tu insères Aladdin (forward
pass). Olivier, Sophie et Alexandra (couche cachée) le décomposent et
identifient progressivement ses caractéristiques. Ils transmettent l’histoire à
Tinou (sortie).







Laisser un commentaire