

« Philosophers have relied on visual metaphors to analyse ideas and explain their theories at least since Plato. Descartes is famous for his system of axes, and Wittgenstein for his first design of truth table diagrams. Today, visualization is a form of ‘computer-aided seeing’ information in data. » (Chen, Floridi, 2013)
Contexte
Le 19 octobre 2018 a eu lieu à l’aula de la HEG-Genève un séminaire s’intitulant « Données – Information ». Celui-ci a été réalisé par trois étudiants du Master en Sciences de l’Information.

Figure 1: Affiche du séminaire « Données – Information »
Sur la base d’articles scientifiques, trois questions principales ont été soulevées par les organisateurs du séminaire (Cevey et al., 2018).
La question « Qu’est-ce que la quatrième révolution au sens de Luciano Floridi ? » m’a particulièrement intéressé car elle annonce un changement de paradigme qui, certes, nous affecte tous, mais qui positionne en quelque sorte les spécialistes des sciences de l’information comme des acteurs pivots. Nous nous retrouvons ainsi au centre des processus pour accompagner au mieux nos publics et trouver des lignes directrices au sein de cette révolution numérique[1].
Le second élément qui m’a marqué fut les nombreuses infographies et icônes utilisées au sein de la présentation. En creusant d’ailleurs les sujets d’intérêt de Luciano Floridi, philosophe de l’information à l’Université d’Oxford, j’ai pu remarquer que la visualisation était une thématique majeure.
Définitions et buts de la visualisation
La visualisation de l’information est une représentation de données dans un espace physique sous la forme de graphiques. De même, la visualisation se réfère autant à la création de représentations appropriées qu’à la transmission/dissémination de ces dernières (Chen, Floridi, 2013).
Pour aller des données vers la connaissance, il faut que celles-ci soient bien formées, significatives et véridiques[2]. La cartographie de la visualisation (voir figure ci-dessous) reprend ces éléments en intégrant différentes étapes nécessaires à la création de ces représentations graphiques. Dans la plupart des applications, la taille totale des données est trop large pour être complément représentée de manière visuelle. Il s’agit donc de sélectionner certaines informations. Ce tri se fait soit par le système, soit par le créateur, soit par l’utilisateur final (Chen, Floridi, 2013).
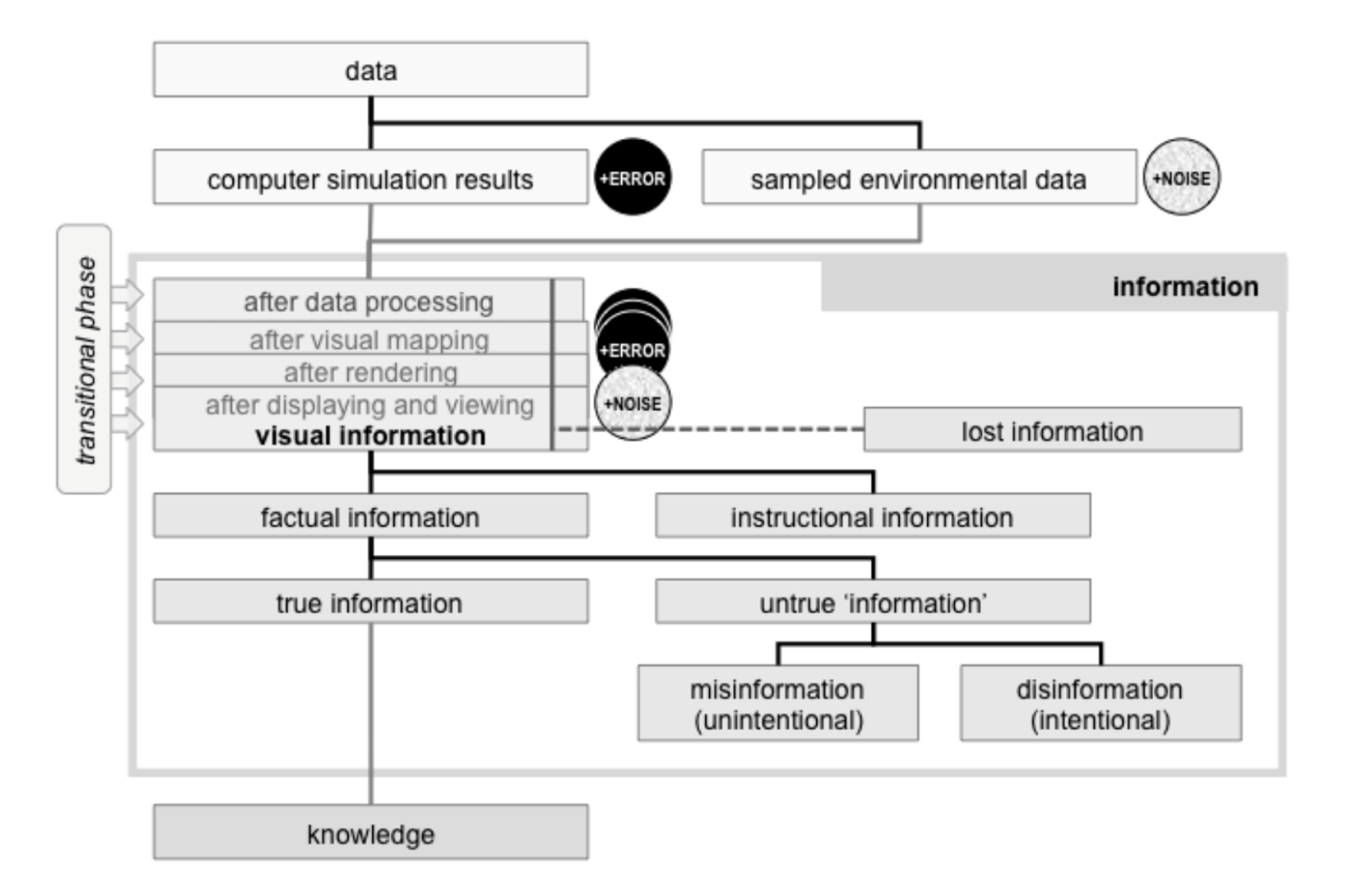
Figure 2: Une cartographie de la visualisation (Chen, Floridi, 2013)
La visualisation a pour but de procurer une meilleure compréhensibilité (gain insight) à leurs utilisateurs. Néanmoins, ceci reste un objectif assez imprécis car difficilement mesurable (Chen et al., 2014). Les mêmes auteurs listent tout de même plusieurs avantages que présentent une visualisation par rapport à une lecture brute des données en prenant l’exemple d’un séismographe :
- Effectuer des observations
- Faciliter la mémorisation externe
- Stimuler la réflexion et engendrer de nouvelles hypothèses
- Évaluer les hypothèses
- Disséminer les connaissances
La seule qualité mesurable de la visualisation des données réside cependant dans le gain de temps de lecture que cela procure aux utilisateurs (Chen et al., 2014). Cet indicateur est particulièrement intéressant dans un monde où la création de données est toujours croissante.
La visualisation dans le contexte du déluge des données
«Information visualization promises to help us speed our understanding and action in a world of increasing information volumes. » (Chen, Floridi, 2013 citant Card, 2007)
A l’ère du zettabyte [3], nous générons une quantité de données de façon exponentielle. Nous avons plus que besoin de synthétiser les informations, de les filtrer et de les mettre sous forme de graphique pour faciliter la lecture.
Lorsque nous croisons une grande quantité de données, des graphiques statiques ne me semblent pas être une réponse suffisante. Il me paraît nécessaire de rendre les visualisations les plus modulaires possibles. L’image ci-dessous est une représentation interactive des influences qu’ont eu les philosophes entre eux. Les données proviennent de triplets RDF (Resource Description Framework) de dbpedia, projet extrayant les données structurées de Wikipédia.

Figure 3: The Philosopher’s Web – source: https://kumu.io/GOliveira/philosophers-web
Ces visualisations devraient être idéalement conçues comme des « périphériques d’entrée » (Jansen, 2014) où l’utilisateur final pourrait lui-même fouiller les données d’une manière interactive. En outre, les nouvelles annotations ou ajouts de données par les chercheurs pourraient, après curation, être intégrées au sein de ces représentations graphiques dynamiques. Chaque contribution deviendrait ainsi un nœud supplémentaire complétant un graphe de connaissances. La visualisation ne serait donc plus un « but en soi » mais une véritable méthode nécessaire à l’heure du Big Data, époque où nous devons faire un tri et gagner du temps pour remplir au mieux nos missions de spécialistes en sciences de l’information.
Bibliographie
CEVEY, Matthieu, COURTIN, Amélie et PERRITAZ, Alex, 2018. Séminaire : Information – Données. In : Master IS. Séminaires [en ligne]. Carouge, Suisse. 19 octobre 2018. [Consulté le 3 novembre 2018]. Disponible à l’adresse : https://prezi.com/p/u9tevnj46lnw/seminaire-information-donnees/.
CHEN, Min et FLORIDI, Luciano, 2013. An Analysis of Information Visualisation. In : Synthese. 2013. Vol. 190, n° 16, p. 3421–3438.
CHEN, Min, FLORIDI, Luciano et BORGO, Rita, 2014. What is Visualization Really for? In : arXiv:1305.5670 [cs]. 2014. p. 75‑93. DOI 10.1007/978-3-319-07121-3_5.
FLORIDI, Luciano, 2011. The philosophy of information. Oxford ; New York : Oxford University Press. ISBN 978-0-19-923238-3.
JANSEN, Yvonne, 2014. Physical and tangible information visualization [en ligne]. PhD Thesis. Paris, France : Université Paris Sud – Paris XI. [Consulté le 3 novembre 2018]. Disponible à l’adresse : https://tel.archives-ouvertes.fr/tel-00981521/document.
Notes
[1] Lire l’article « De l’importance d’une éthique dans l’infosphère : la quatrième révolution technologique selon Luciano Floridi » écrit par ma camarade Anouk Santos pour plus de précisions.
[2] Il s’agit de la définition de l’information selon Luciano Floridi (2011) : « well-formed, meaningful and truthful data ».
[3] Un zettabyte représente 1021 bytes, autrement dit 1 milliard de téraoctet.