

Par Christelle Donius et Anna Hug Buffo
“Internet n’oublie jamais.”
Cet adage est fréquemment employé par des parents, anxieux que leurs enfants adolescents ne publient en ligne des photos compromettantes ou d’autres contenus qui s’avéreraient gênants par la suite.
Leur modèle centralisé leur facilite par ailleurs cette tâche du point de vue technique et organisationnel.
Les autres sites du web, qui ne prétendent pas un tel intérêt économique sous-jacent, ne sont en général pas préservés de la même manière par leurs auteurs.
Pixar (via drweb.de)
Selon la méthode d’évaluation utilisée, la durée moyenne de vie d’une page web est estimée à 44 jours (Kahle 1997), 75 jours (Guy 2009), ou encore à 2 ans et 7 mois (Crestodina 2017). Une étude a montré que près d’un tiers des liens cités dans les articles scientifiques n’étaient plus fonctionnels, 5 ans après publication (Sampath Kumar et al. 2015). Cela semble confirmer que l’adage ne s’applique apparemment pas à l’ensemble du web, mais peut-être seulement aux contenus des réseaux sociaux.
Des initiatives existent
Heureusement, comme nous l’avions mentionné dans notre dernier billet de blog, des initiatives luttent contre la disparition fatale de sites :
- De nombreuses bibliothèques nationales préservent le patrimoine du web en lien avec un pays donné.
- Des universités ou institutions culturelles archivent les sites liés à des domaines thématiques particuliers.
- Des acteurs à but lucratif, ayant découvert ce marché depuis peu, permettent désormais à des entreprises ou tout autre type d’entités de procéder à un archivage sur mesure des sites qu’elles gèrent.
Internet Archive (IA), pionnier dans le domaine qui ne souhaite pas moins que de créer une nouvelle bibliothèque d’Alexandrie sous forme numérique, a une approche particulièrement large en la matière. Des collections entières (par exemple 490’000 morceaux de musique que MySpace pensait avoir perdu au printemps 2019) sont moissonnées, et aucune différence n’est faite entre des informations “dignes de préservation” ou “sans valeur”. La fondation privée à but non lucratif collabore avec d’autres initiatives en ligne, notamment Wikipédia. En effet, pour pallier les liens brisés de la rubrique “sources” de l’encyclopédie en ligne, un logiciel automatique remplace ceux dont la cible a disparu par un lien vers IA, si ce même contenu s’y trouve.

Exemple d’un lien vers IA dans la page Wikipédia (en anglais) consacrée aux archives (https://en.wikipedia.org/wiki/Archive)
On constate donc des efforts, au niveau mondial, en ce qui concerne la préservation du patrimoine du web. Néanmoins, tout ne saura être archivé, principalement pour des raisons techniques : la structure compliquée des pages web et la pluralité des formats rendent la pérennisation très difficile, sans parler du renouvellement fréquent des contenus.
Les cordonniers sont souvent le plus mal chaussés…
… et les acteurs de l’archivage du web ne sont pas à l’abri de la situation qu’ils déplorent !
Un exemple est l’initiative NEDLIB (Networked European Deposit Library), un projet mis en place par l’Union européenne dans les années 1997 à 2000 pour développer l’infrastructure nécessaire à la préservation à long terme de ressources électroniques parmi lesquelles des sites web. Diverses publications scientifiques (Hakala 2003, 2004, Chaimbault 2008) citent des liens à ce sujet, mais les sites consacrés à cette collaboration sont inactifs aujourd’hui…
 |
 |
Sources : journal en ligne de la Bibliothèque nationale de Finlande / dossier documentaire sur l’archivage du web (https://www.kansalliskirjasto.fi/extra/tietolinja/0203/webarchive.html)
 |
 |
Source : Bibliothèque nationale des Pays-Bas (https://www.kb.nl/coop/nedlib)
On peut également mentionner la European Archive Foundation (précédemment Internet Memory Foundation), qui se voulait l’émule européenne d’Internet Archive. Depuis août 2018, elle a disparu de la circulation : ses URL internetmemory.org et archivethe.net ne sont plus actives. Il n’existe aucune information concernant les contenus archivés durant la décennie d’activité de la fondation. Peut-être la seule réminiscence de ce projet ambitieux est une autre de ses URL, europarchive.org. Il y a moins de trois ans, cette même URL permettait encore d’accéder à une collection de musique classique, de films documentaires créés par le gouvernement britannique et de sites web archivés :
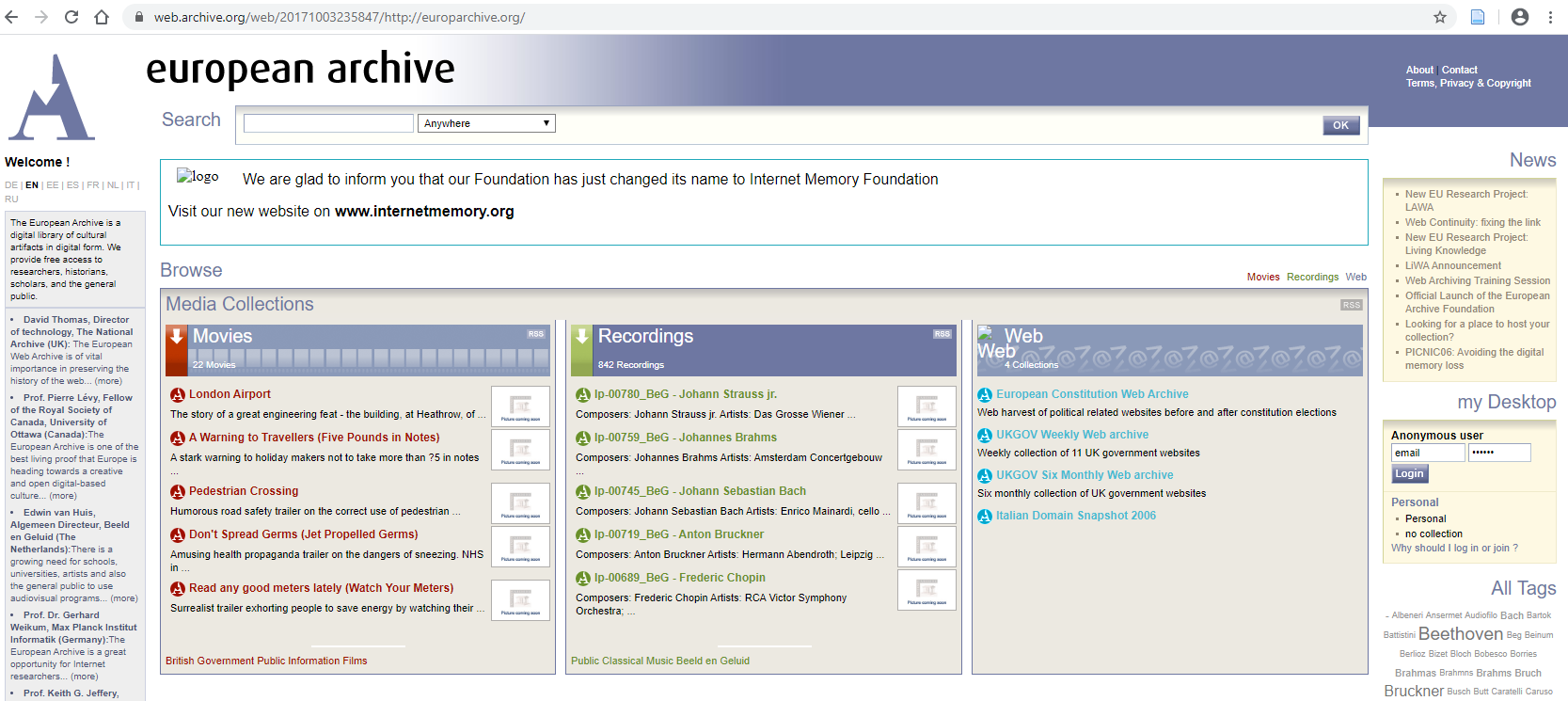
Source : Internet Archive, capture du 3 mars 2017 (https://web.archive.org/web/20171003235847/http://europarchive.org/)
Mais aujourd’hui, il semble avoir été récupéré par un “magazine” pas très scientifique…

Source : europarchive.org
L’immuabilité n’est pas
En définitive, la pérennité des archives du web est tributaire de celle des initiatives qui se préoccupent de leur collecte. Ainsi, une répartition de la charge de travail entre différents acteurs est certainement une bonne chose. Internet Archive agit depuis plus de vingt ans, nous pouvons probablement y placer notre confiance. Néanmoins, même cette vénérable institution ne saurait être à l’abri d’un déclin, par exemple après la disparition de son fondateur – même si nous ne le souhaitons pas ! Dès lors, les acteurs publics patrimoniaux devraient réfléchir à un stratagème permettant d’augmenter la part du web préservé par leur soins. Malgré un budget relativement restreint, ils font déjà un travail remarquable à leur niveau, comme nous le relatons dans notre rapport de recherche. Mais une approche purement sélective, telle que pratiquée par la Bibliothèque nationale suisse, n’est peut-être plus suffisante.
Bibliographie
CHAIMBAULT, Thomas, 2008. L’archivage du web : dossier documentaire [en ligne]. Villeurbanne : Enssib. [Consulté le 19 décembre 2019]. Disponible à l’adresse : https://www.enssib.fr/bibliotheque-numerique/notices/1730-l-archivage-du-web
CRESTODINA, Andy, [2017]. What is the average website lifespan? 10 factors in website life expectancy. Orbit Media Studios [en ligne]. [2017]. [Consulté le 19 décembre 2019]. Disponible à l’adresse : https://www.orbitmedia.com/blog/website-lifespan-and-you/
GUY, Marieke, 2009. What’s the average lifespan of a Web page? JISC PoWR [en ligne]. 12 août 2009. [Consulté le 19 décembre 2019]. Disponible à l’adresse : https://jiscpowr.jiscinvolve.org/wp/2009/08/12/whats-the-average-lifespan-of-a-web-page
HAKALA, Juha, 2003. Archiving the Web: European experiences. Presentation in CONSAL XII, 20-23 October 2003, Brunei. Tietolinja [en ligne]. No 02/2003. [Consulté le 19 décembre 2019]. Disponible à l’adresse : https://www.kansalliskirjasto.fi/extra/tietolinja/0203/webarchive.html
HAKALA, Juha, 2004. Archiving the Web: European experiences. Program [en ligne]. 1er septembre 2004. Vol. 38, no 3, p. 176-183. [Consulté le 19 décembre 2019]. Disponible à l’adresse : https://www.emeraldinsight.com/doi/full/10.1108/00330330410547223 [accès par abonnement].
KAHLE, Brewster. Preserving the Internet. Scientific American [en ligne]. Mars 1997. [Consulté le 19 décembre 2019]. Disponible à l’adresse : https://www.scientificamerican.com/article/preserving-the-internet [accès par abonnement].
SAMPATH KUMAR, B. T., VINAY KUMAR, D et PRITHVIRAJ, K. R., 2015. Wayback machine: reincarnation to vanished online citations. Program. 2015. Vol. 49, no 2, p. 205‑223. DOI 10.1108/PROG-07-2013-0039.
Laisser un commentaire