

Par Florence Burgy, Steeve Gerson et Loïc Schüpbach
NB: Ce billet de blog fait état de l’avancement de notre projet au 23 décembre 2019. Au moment de sa publication, ce projet est terminé, et les résultats finaux ne sont pas ceux présentés dans ce billet.

Figure 1 : Collection de Bry, livre I, page 43, et sa transcription avec Tesseract, modèle anglais
De litteris et numeris – des lettres et des chiffres
Notre projet, Ex imagine ad litteras, « de l’image aux lettres » en français, consiste à océriser la collection De Bry, des imprimés latins de la Renaissance, afin d’en obtenir une transcription aussi fidèle que possible et permettre ainsi la recherche plein texte. Pour plus d’informations, nous vous invitons à aller consulter notre premier billet de blog qui décrit ce projet plus en détails.
Premiers tests
À ce jour nous avons testé plusieurs logiciels d’océrisation, dont trois principalement : Kraken, OCR4all et Tesseract. Pour chacun, nous avons utilisé plusieurs modèles, c’est-à-dire plusieurs algorithmes pré-entraînés avec des jeux de données représentatifs d’une langue (anglais, latin, espagnol etc.) et/ou d’un type de police de caractères (Antiqua, Fraktur etc.). Notre travail a donc consisté à transcrire un jeu de test de 29 images choisies au hasard à l’aide des différents modèles de ces logiciels, afin de déterminer lesquels donnent les meilleurs résultats.
Métriques et résultats
Pour ce faire, nous nous sommes servis de métriques usuelles des Sciences de l’Information, à savoir la précision et le rappel, à la fois à l’échelle des caractères et à l’échelle des mots. En tout, nous avons testé plus d’une quinzaine de modèles différents. L’image ci-dessous, tirée d’un poster scientifique créé dans le cadre de ce projet, permet de visualiser les meilleurs résultats obtenus pour chacun des trois logiciels cités plus haut.
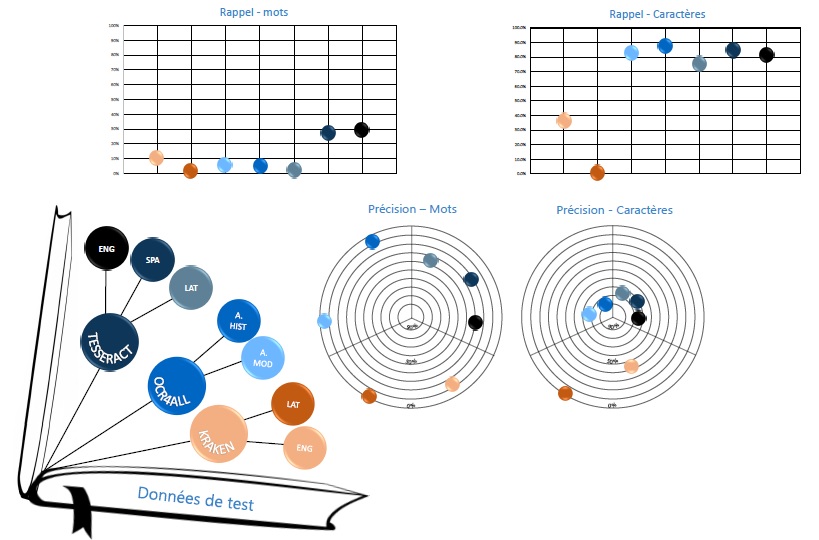
Victoria vel clades ? – des résultats qui interrogent
Comme l’image ci-dessus le montre, les meilleurs modèles pour océriser la collection de Bry selon nos tests sont Tesseract, modèle anglais, et OCR4all, modèle Antiqua historique. Les résultats sont cependant troublants et soulèvent différentes questions, auxquelles nous nous proposons de répondre.
Les modèles latins, peu performants
Il est étonnant que les modèles latins, pourtant dans la même langue que la collection de Bry, soient moins performants que d’autres. Cela s’explique par l’importance de la police de caractères : si les données d’entraînement du modèle latin utilisent une police très différente de celle de la collection de Bry, la reconnaissance en sera moins optimale.
En outre, les performances des modèles dépendent également de leur propre entraînement. Les modèles de Tesseract sont entraînés grâce à des données provenant de partout sur le web. Ainsi, certaines langues, comme l’anglais et l’espagnol, permettent de créer des jeux de données immenses et diversifiés, alors que pour le latin, comme pour d’autres langues plus rares, la quantité de données à disposition est moindre, et les résultats en pâtissent.
Le fossé entre les résultats au niveau des caractères et au niveau des mots
Cette différence s’explique essentiellement par des raisons mathématiques. En effet, si un caractère est incorrect dans un mot de 10 lettres, la précision au niveau des caractères sera de 90%, alors qu’au niveau des mots, elle sera de 0%. Les chiffres dégringolent alors rapidement.
De rebus futuris – et la suite ?
Pour la suite de ce projet, notre choix s’est porté sur Tesseract, du fait non seulement de ses performances, mais aussi de sa simplicité d’utilisation. En effet, OCR4all et Kraken peinent à traiter les pages sans texte, et tournent en boucle sans donner de message d’erreur, rendant ainsi l’attente longue et vaine ; problème que Tesseract ne pose pas. Nous avons donc trois directions possibles.
Tesseract – modèle anglais paramétré
Nous pouvons choisir le modèle le plus performant de Tesseract, le modèle anglais, et tenter de jongler avec les paramètres pour obtenir une transcription plus fidèle. Cette possibilité est cependant chronophage, et les résultats ne sont pas assurés.
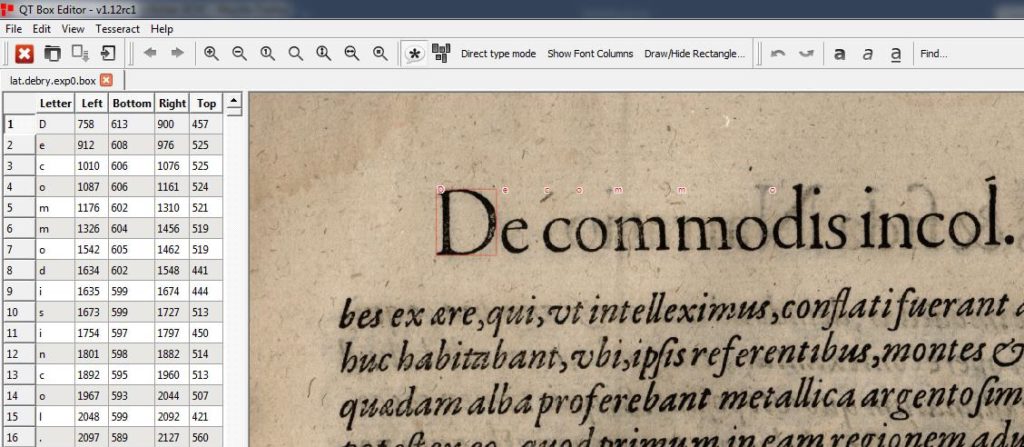
Tesseract – modèle « maison »
Il est en outre possible de créer notre propre modèle pour Tesseract. Cela consiste à donner quelques images de notre jeu de données au logiciel, et à indiquer manuellement la valeur des caractères. Ce travail, quoique laborieux, peut cependant apporter de très bons résultats car le modèle sera alors adapté aux polices d’écriture utilisées dans la collection de Bry. Cette solution a cependant le désavantage de créer un modèle à usage très spécifique, qui ne sera peut-être pas réutilisable pour d’autres documents.
Post-correction et machine learning
La dernière solution, compatible avec les deux précédentes, est le traitement automatique des outputs de l’OCR, soit par des scripts visant à réguler certaines erreurs fréquentes, soit par des outils de post-correction, comme par exemple PoCoTo, un outil open source que nous souhaitons tester. En outre, des solutions utilisant du machine learning sont envisageables pour optimiser les résultats et, par exemple, pour permettre de résoudre les abréviations, problématique connue en latin. Nous verrons lesquelles de ces options sont envisageables d’ici la fin de ce projet. Tempus fugit.
Laisser un commentaire