

Manon Bari, Manuela Bezzi, Marielle Guirlet
Mai 2019 : nous rendons le cahier des charges de notre projet de recherche. Celui-ci, encadré par Basma Makhlouf-Shabou, concerne les dispositifs d’e-learning en gestion des données de recherche pour le projet DLCM (Burgi, Blumer 2018). La prochaine étape est de produire un rapport de gestion des données.
Données … données … mais quelles données ?
Ce projet reposant surtout sur une revue de l’existant et sur l’évaluation de formations pour établir un devis de MOOC, nous manipulerons et gérerons en grande partie des données qualitatives.
Pour deux d’entre nous au parcours scientifique, cela est nouveau et plutôt déroutant : quoi, pas d’observations ? Pas de mesures quantitatives ? Même pas de code ? Dans ce contexte, allons-nous quand même générer des données ?
De plus, il nous semble que les outils de gestion de données les plus utilisés traitent rarement de données qualitatives. Ainsi, les concepts de cycle de vie et de réutilisation future nous semblent dans notre cas encore abstraits.
Il est temps de se replonger dans le cours de Gestion des Données de Recherche du premier semestre du Master IS (Schneider 2018) et de prendre les choses dans l’ordre.
Par analogie avec la pyramide d’Andorfer (Andorfer 2015) (figure 1) citée dans la partie du cours sur les données des humanités, nous identifions trois catégories de données pour notre projet.
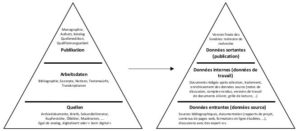
Figure 1 : Pyramide d’Andorfer (Andorfer 2015) (à gauche) et transposition à notre projet (à droite).
Les données source forment la base de la pyramide. Dans notre cas, ces données entrantes proviennent de sources bibliographiques, de documentation au sens large (rapports de projets, contenus de pages web, formations en ligne étudiées, …) et de discussions avec des expert-e-s.
Au milieu de la pyramide se trouvent les données internes (ou données de travail). Elles se trouvent dans les documents que nous aurons rédigés après sélection, remaniement, traitement, enrichissement des données source (notes de discussion, comptes-rendus de lecture, d’études de cas, versions de travail de documents à livrer) ; et certains outils que nous concevrons (grille de lecture par exemple) – nous allons donc bien « générer des données » !
Les données de la pointe de la pyramide sont les données sortantes, sous forme de publication pour Andorfer. Pour notre projet, elles correspondent à la version finale des livrables que nous produirons, dont le mémoire de recherche qui inclura certains des autres livrables, comme le devis de MOOC.
L’OCDE définit les données de la recherche comme « des enregistrements factuels (chiffres, textes, images et sons), qui sont utilisés comme sources principales pour la recherche scientifique et sont généralement reconnus par la communauté scientifique comme nécessaires pour valider des résultats de recherche.” (OCDE 2007, p.19).
Pour l’Université de Bristol, « Research data is often arranged or formatted in a such a way as to make it suitable for communication, interpretation and processing. Put more simply, research data is all of the information that you use as an integral part of your research. » (University of Bristol [sans date], section 2).
Le mémoire de recherche incluant la bibliographie et certaines données internes et sortantes contiendra donc l’essentiel de nos données de recherche selon ces définitions.
Et maintenant… on en fait quoi ?
Nous adaptons alors le cycle de vie des données du projet DLCM (DLCM 2018) à notre contexte (figure 2).
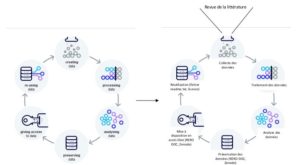
Figure 2 : Cycle de vie des données DLCM (DLCM 2018) (à gauche) et transposition à notre projet (à droite).
Creating se traduit par la collecte des données entrantes.
Processing correspond à une sélection plus fine, au remaniement, au traitement, à l’enrichissement de données.
Analysing conduit ensuite à la production de documents (sous forme textuelle, graphique, ou de tableaux).
Répondre aux 20 questions de David Shotton (Shotton 2012; sous licence Creative Commons Attribution 3.0 Unported License) nous aide à préciser les étapes suivantes du cycle de vie.
Pendant le projet, nous stockons nos données sur SWITCHdrive (avec l’assurance que les données restent en Suisse) en suivant une convention de nommage des fichiers et dossiers. La gestion des sources bibliographiques et leur référencement se fait dans Zotero. Nous utilisons ces deux services en mode collaboratif, partagés entre nous et avec l’équipe encadrante. Nous mettons en place un calendrier de sauvegardes incluant également les versions de documents en cours d’élaboration sur nos ordinateurs personnels.
Le dépôt éventuel du mémoire sur RERO DOC[1] s’accompagnera de la création de métadonnées de préservation. Nous déposerons également notre mémoire sur Zenodo où des métadonnées, dont un DOI, lui seront attribuées. Dans les deux cas, les métadonnées seront conformes au protocole OAI-PMH (Zenodo 2017, RERO DOC [sans date]). Sur ces deux dépôts, le mémoire sera disponible sans restriction d’accès, participant ainsi à la fois au Preserving et au Giving access.
Re-using data: sur Zenodo, un fichier readme.txt détaillera la source des données et notre démarche. Afin d’éviter l’utilisation à des fins commerciales du devis de MOOC par des tiers, nous déposerons le mémoire sous licence CC BY-NC 4.0.
Et finalement…
Juin 2019 : Données identifiées, cycle de vie précisé, procédures de mise en œuvre pratique spécifiées: nous sommes maintenant prêtes à gérer nos données de recherche tout au long de leur cycle de vie, depuis le début du projet jusqu’après sa fin, en ayant fait en sorte que nos résultats soient vérifiables et nos données réutilisables.
[1] En cas de note égale ou supérieure à 5, le mémoire sera déposé et publié sur RERO DOC.Bibliographie
ANDORFER, Peter, 2015. GOEDOC – Dokumenten – und Publikationsserver der Georg-August-Universität Göttingen – Forschungsdaten in den (digitalen) Geisteswissenschaften – Versuch einer Konkretisierung [en ligne]. 2015. S.l. : s.n. [consulté le 23 juin 2019]. Disponible à l’adresse : http://webdoc.sub.gwdg.de/pub/mon/dariah-de/dwp-2015-14.pdf
BURGI, Pierre-Yves, BLUMER, Eliane, 2018. Le projet DLCM : gestion du cycle de vie des données de recherche en Suisse. Alice Keller & Susanne Uhl. Bibliotheken der Schweiz: Innovation durch Kooperation. Festschrift für Susanna Bliggenstorfer anlässlich ihres Rücktrittes als Direktorin der Zentralbibliothek Zürich. Berlin : De Gruyter [en ligne]. 2018. p.235-249. [Consulté le 28 juin 2019]. Disponible à l’adresse : https://archive-ouverte.unige.ch/unige:105931
DLCM, 2018. Data Management Checklist [en ligne]. Version 1.1. Janvier 2018. [Consulté le 23 juin 2019]. Disponible à l’adresse: https://www.dlcm.ch/resources/dlcm-dmp
OCDE, 2007. Principes et lignes directrices de l’OCDE pour l’accès aux données de la recherche financée sur fonds publics [en ligne]. [Consulté le 25 juin 2019]. Disponible à l’adresse : http://www.oecd.org/fr/science/inno/38500823.pdf
RERO DOC [sans date]. RERO DOC Bibliothèque numérique [en ligne]. [Consulté le 28 juin 2019]. Disponible à l’adresse : https://doc.rero.ch/help/harvest
SCHNEIDER, René, 2018. Les données de la recherche dans les sciences humaines [document pdf]. Support de cours : Cours « Gestion des données de recherche, Module Recherche Scientifique I », Haute école de gestion de Genève, filière Information documentaire, année académique 2018-2019.
SHOTTON, David, 2012. Twenty Questions for Research Data Management. Data Management Planning [en ligne]. 7 mars 2012. 9 mai 2013. [Consulté le 23 juin 2019]. Disponible à l’adresse: https://datamanagementplanning.wordpress.com/2012/03/07/twenty-questions-for-research-data-management/
University of Bristol [sans date]. Research Data Bootcamp: What counts as research data? https://data.blogs.bristol.ac.uk/bootcamp/ [en ligne]. [Consulté le 23 juin 2019]. Disponible à l’adresse: https://data.blogs.bristol.ac.uk/bootcamp/data/
Zenodo, 2017. Principles. about.zenodo.org [en ligne]. [Consulté le 25 juin 2019]. Disponible à l’adresse: http://about.zenodo.org/principles/
Laisser un commentaire