

Par Christelle Donius et Anna Hug Buffo
Le site web de la HES-SO Genève. Celui de l’Association vaudoise des archivistes. Ou encore celui de la dessinatrice Albertine… Ces trois contenus sont considérés comme éléments du patrimoine numérique suisse. Ils sont, par conséquent, régulièrement archivés par la Bibliothèque nationale (BN) dans le cadre de son mandat de préservation des publications électroniques en lien avec la Suisse : les e-Helvetica. Cette collection numérique est gérée en partenariat avec les bibliothèques cantonales et d’autres institutions spécialisées. Le document Archives web suisse : bases présente la genèse de ce service établi en 2008.
Le web suisse est donc archivé – ou du moins, la partie qui est évaluée comme digne de conservation. Car la sélection est assez restreinte : la BN indique que ses collections comprennent “plus de 10’000 sites web”[1], tandis que le registrar officiel du domaine .ch, Switch, annonce plus de 2,2 millions de sites avec cette terminaison au 15 juin 2019[2]. Sans parler de sites d’autres top level domains qui pourraient aussi être qualifiés de “suisses”, tels que www.swiss.com (naturellement pris en charge par le programme d’archivage de la BN[3]).
Deux approches différentes d’archivage du web
Notre projet de recherche vise à explorer l’étendue de la couverture de l’archivage appliqué par la BN, et surtout à comparer son approche avec celle d’un autre acteur de l’archivage du web : Internet Archive (IA). Cette initiative américaine à but non lucratif archive des contenus numériques de toutes sortes, dont des pages web. Elle pratique des moissonnages à grande échelle à l’aide de crawlers qui enregistrent tout ce qu’ils trouvent en passant d’un lien à l’autre. Depuis 1996, IA a ainsi enregistré plus de 330 milliards de pages web, avec parfois plus de 200 versions capturées à des instants différents.
Pour permettre la consultation, elle propose l’application web “Wayback Machine”, permettant un voyage à travers le temps par le visionnage de sites datant de la genèse du web, avec des pages aux graphismes et fonctionnalités désuets, témoignage de l’évolution des technologies du web.
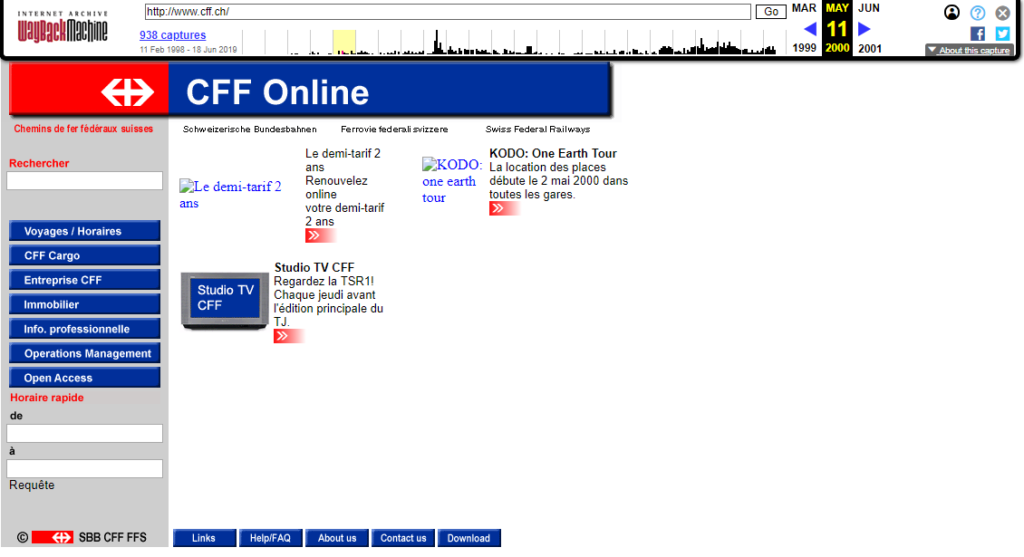
La matière brute de notre recherche
Avant de procéder à toute collecte, il faut déterminer ce que l’on cherche à collecter. Dans le cadre de cette recherche, il s’agit d’évaluer une représentativité. Cette analyse n’ayant encore jamais été entreprise à notre connaissance, nous avons opté pour une cartographie globale des contenus archivés par les deux institutions. Concrètement, nous nous limiterons au niveau des URL et du nombre de versions présentes dans les archives web. La complétude des sous-pages de chaque site ne sera pas explorée, d’autant plus qu’il s’agit d’une valeur à très forte variation.
Quels sites (suisses) sont présents uniquement dans IA, respectivement à la BN ? Quel pourcentage se recoupe ? Quelle période temporelle est couverte ? Telles sont les questions que nous nous posons.
API et autres interrogations
Pour pouvoir consulter les sites archivés par la BN, il faut se rendre dans une institution partenaire, en raison de la limitation de consultation imposée le respect du droit d’auteur. IA est moins restrictif et permet l’accès en ligne à la grande majorité de ses contenus. Mais dans les deux cas, la liste des sites web conservés est disponible par le biais de catalogues, agrémentés de moteurs de recherche : Wayback Machine, outil maison d’IA, et Helveticat, qui recourt à l’outil de découverte Primo pour présenter le fonds de la BN. Nous avions donc d’abord pensé à crawler les pages de résultats de recherches, à l’aide de logiciels et de requêtes particulières (par exemple, “xwas” + le sigle d’un canton pour accéder aux sites liés à celui-ci et archivés par la BN). Ces outils sont très efficaces pour un utilisateur grand public qui souhaite parcourir des informations générales ou un site en particulier. Mais ils trouvent vite leurs limites lorsqu’il s’agit de récolter les données qui nous importent : le nombre de pages de résultats est limité, le design est peu favorable à une automatisation de la collecte, les métadonnées offertes ne sont pas exhaustives.
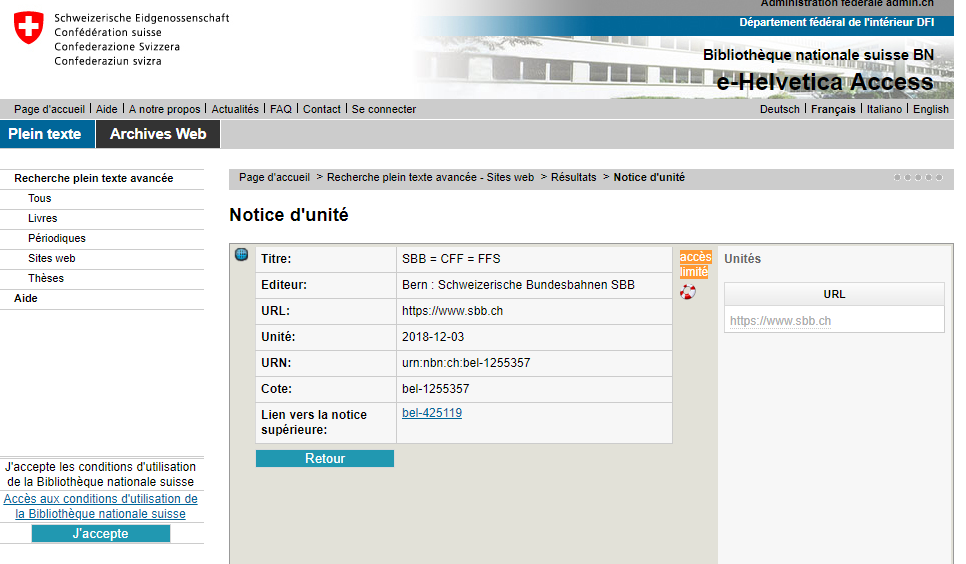
Des investigations un peu plus poussées nous ont conduites à d’autres outils pour chacune des institutions. Ainsi, la BN dispose d’un autre moteur de recherche avancée permettant un téléchargement de notices groupées, mais avec très peu de métadonnées. Du côté IA, une interface graphique documentée permet une recherche avancée selon le type de métadonnées et leur téléchargement sous format JSON, RSS, XML ou CSV.

Contact personnel indispensable
À l’issue de ces premières investigations, il nous semble difficile d’obtenir une liste complète de toutes les références conservées. Aussi, nous avons établi que pour la BN, il sera indispensable de directement demander les ressources dont nous avons besoin, afin de garantir une qualité des données suffisante pour notre analyse. Pour IA, les solutions proposées sont vastes et doivent encore faire l’objet de tests de potentiel. Selon notre niveau de satisfaction à la suite de cette exploration, nous n’excluons pas une prise de contact pour obtenir notre matière première. Dans les deux cas, le lien avec les organisations “récolteuse” est important pour connaître les modalités d’interrogation des outils proposés, mais surtout pour accéder à l’exhaustivité des données nécessaires à notre analyse.
Notes
[1] https://www.nb.admin.ch/snl/fr/home/collections/collections-bibliotheque/sites-web.html
[2] https://www.nic.ch/fr/statistics
[3] https://nb-helveticat.primo.exlibrisgroup.com/discovery/search?vid=41SNL_51_INST:helveticat&query=any,contains,sz001766807&lang=fr