

New York, 26 octobre 2018, lors d’une vente aux enchères organisée par la célèbre maison Christies, une impression sur toile représentant le portrait d’un certain Edmond de Belamy se vend pour 432’500 USD. Entourée d’un cadre en bois doré d’un autre siècle, la peinture est comme inachevée, le trait est maladroit, le visage de l’homme est flou. En bas du tableau, en guise de signature, on distingue une étrange formule mathématique.

Cette œuvre est en fait la matérialisation des recherches du collectif français Obvious, qui travaille sur l’intelligence artificielle. Quant à Edmond de Belamy, il n’existe pas ! C’est en réalité un clin d’œil à Ian J. Goodfellow, chercheur américain qui travaille notamment sur le Machine Learning et dont l’apport sur les Generative Adversarial Nets (GANs) a inspiré les trois fondateurs d’Obvious, Pierre Fautrel, Hugo Caseles-Dupré et Gauthier Vernier.
Comment une intelligence artificielle peut-elle créer une œuvre d’art ?
Pour comprendre comment une machine peut se cacher derrière la paternité d’une telle œuvre (d’art ?), il faut se plonger dans les aspects techniques.
Dans une première étape, le collectif Obvious a sélectionné 15’000 portraits peints entre le XVIIIe et le XXe siècle, qui constituent le training set (distribution de base), c’est à dire l’échantillon sur lequel la machine va pouvoir s’entrainer. L’idée a ensuite été de développer un modèle et des algorithmes pouvant extraire et interpréter les données contenues dans ces tableaux, soit autant de caractéristiques définissant les œuvres d’art de cette période.
Dans cette optique, ils ont utilisé des réseaux de neurones artificiels en tant que modèles génératifs, qu’ils ont entraîné grâce aux différentes données extraites des 15’000 portraits afin de créer la peinture d’Edmond de Belamy. Ces modèles génératifs sont capables de déceler et de consigner automatiquement et sans intervention humaine (on parle d’apprentissage non supervisé) les caractéristiques essentielles des images afin d’en générer de nouvelles par la suite.
Un deuxième réseau discriminateur (Discriminator) a ensuite été introduit pour essayer de déterminer si une image d’entrée provenait de la distribution de base ou si elle avait été générée par le premier réseau (Generator).
Les Generative Adversarial Networks
C’est ce qu’on appelle les réseaux antagonistes génératifs (Generative Adversarial Networks, GANs). Deux réseaux travaillent en opposition l’un contre l’autre dans un processus d’entrainement qui s’apparente à un jeu.
Le premier réseau, celui du générateur, génère des images en se basant sur la distribution de base (training set). Son but est d’essayer de tromper son adversaire, le discriminateur, en s’efforçant de lui faire croire que ce qu’il a généré provient en réalité de la distribution de base.
Le deuxième réseau, celui du discriminateur, examine les images et s’emploie à distinguer si elles proviennent de la distribution de base (real) ou si elles sont produites par le générateur (fake).
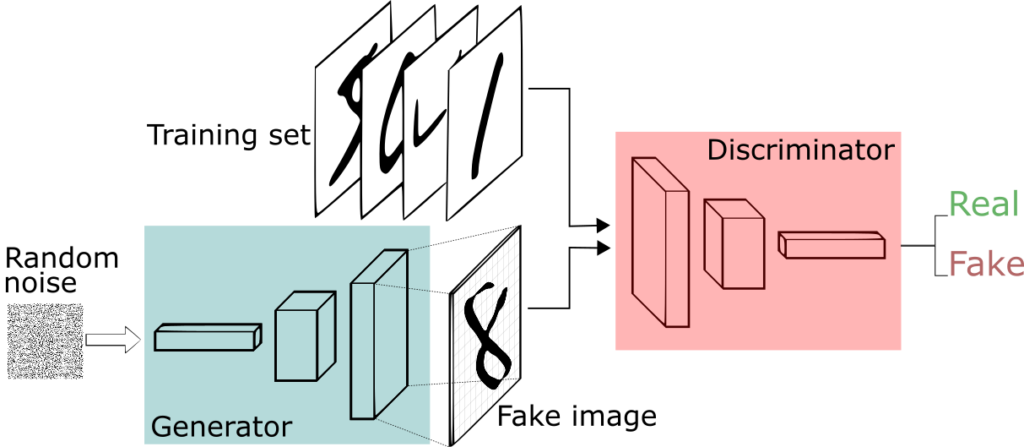
Lorsque le discriminateur parvient à distinguer une différence entre les deux distributions, le générateur modifie ses paramètres et tente de s’améliorer jusqu’à ce qu’il parvienne à tromper complètement le discriminateur. A ce moment là, les deux distributions se confondent, le discriminateur ne sait plus différencier si les images qu’on lui soumet sont créées par le générateur ou si elles proviennent des données d’apprentissage (training set).
Le but est donc de faire en sorte que la distribution générée par le discriminateur coïncide le plus possible avec les données d’apprentissage. L’œuvre qui en résulte est donc originale puisqu’elle n’est pas la copie d’un tableau existant. C’est un peu comme si un élève des beaux arts s’était inspiré du travail de Picasso pour peindre un tableau dans le même style que le grand maître, tout en conservant une part de singularité.
Pour aller jusqu’au bout du processus, Obvious a ensuite imprimé le résultat sur une toile pour être plus tangible, pour gagner en visibilité, mais aussi pour espérer se faire une place à part entière dans le milieu très conservateur de l’art. Et au vu du succès de la vente aux enchères, leur démarche a été payante !
Naissance d’un nouveau mouvement artistique ?
Les membres d’Obvious n’ont pas été les premiers à exploiter le potentiel créatif de l’intelligence artificielle. En 2016, des historiens de l’art, des scientifiques et des développeurs avaient réalisés, en partenariat avec Microsoft, un tableau imitant le style du peintre Rembrandt.
“Can the great master be brought back to create one more painting ?” The Next Rembrandt
Le résultat, intitulé The Next Rembrandt, est d’ailleurs bien plus précis que le portrait d’Edmond de Belamy.

Nous assistons peut-être, comme le prétend François Chollet, chercheur en intelligence artificielle, à l’émergence d’un nouveau mouvement artistique, le GANisme, où l’homme s’associe à la machine pour augmenter son potentiel créatif.
“Creativity isn’t just for humans” devise du collectif Obvious
Le débat reste ouvert pour savoir si un tel procédé est réellement créatif et si une intelligence artificielle peut prétendre être une artiste. Elle est certes capable de créer une œuvre à part entière, sans intervention humaine (ou presque), mais peut-elle vraiment nous transmettre une émotion ? Peut-elle différencier ce qui est beau ?
L’histoire de l’art a en tout cas toujours permis d’appréhender, au delà de l’œuvre elle-même, le monde qui nous entoure. L’œuvre nous parle de l’histoire de l’homme et des civilisations, elle est le reflet de nos préoccupations, des avancées techniques et scientifiques. Un jour peut-être que la machine sera même capable d’aller plus loin en parvenant à déchiffrer son environnement et à le retranscrire dans une œuvre originale qui lui sera propre.
Pour aller plus loin :
CASELLES-DUPRE, Hugo, 2018. Obvious, explained. Medium [en ligne]. 14 février 2018. [Consulté le 25 novembre 2018]. Disponible à l’adresse : https://medium.com/@hello.obvious/ai-the-rise-of-a-new-art-movement-f6efe0a51f2e
GOODFELLOW, Ian J. et al., 2014. Generative Adversarial Net. 10 juin 2014 [Consulté le 25 novembre 2018]. Disponible à l’adresse : https://arxiv.org/pdf/1406.2661.pdf
RADFORD, Alec, METZ, Luke, CHINTALA, Soumith, 2016. Unsupervised representation learning with deep convolutional generative adversarial networks. CoRR [en ligne]. 7 janvier 2016. [Consulté le 25 novembre 2018]. Disponible à l’adresse : https://arxiv.org/pdf/1511.06434.pdf
USI Events, 2015. Deep Learning : Yann LeCun à l’USI [enregistrement vidéo]. YouTube [en ligne]. 13 juillet 2015. [Consulté le 25 novembre 2018]. Disponible à l’adresse : https://www.youtube.com/watch?v=RgUcQceqC_Y
Laisser un commentaire