

Le code… une data pas comme les autres…
Le partage du code source est devenu un élément essentiel de la recherche reproductible. La question n’est plus seulement de publier, mais de publier « FAIR », ou plus exactement « FAIR4S » (for software)[1]. Ceci commence par la publication du code sur un dépôt.
Pourtant, les pratiques observées dans la littérature biomédicale montrent une grande hétérogénéité dans la manière de documenter, licencier et déposer ces codes.
- Parmi les 57 articles scientifiques liés à du code issus de PubMed qui font l’objet de notre étude exploratoire, 40 ont leur code géré sur GitHub (70%).
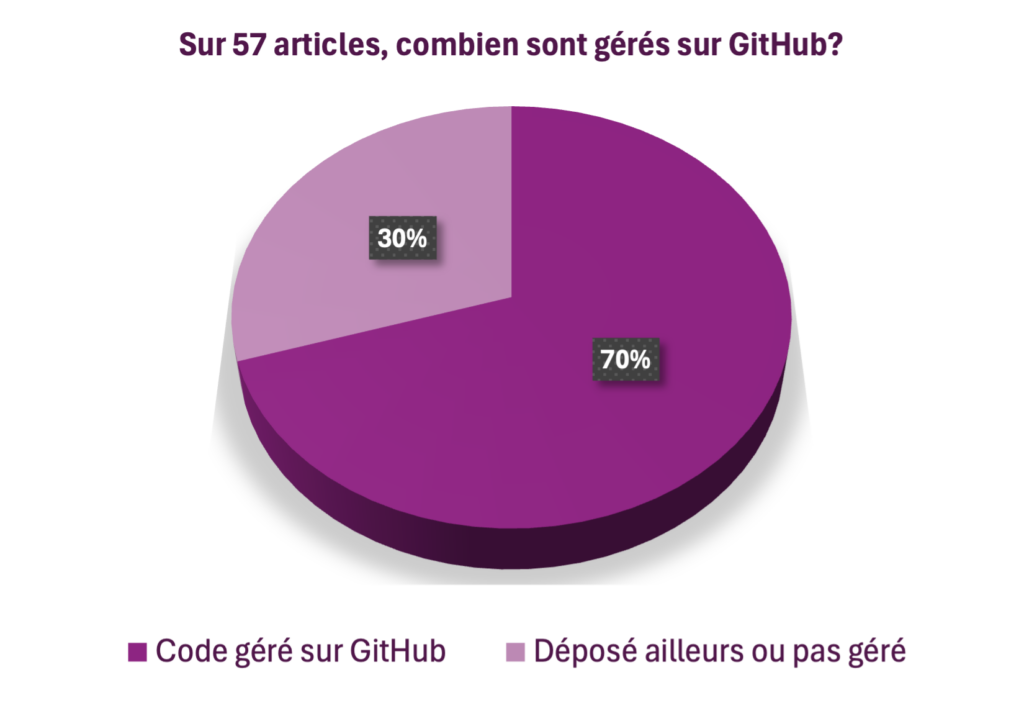
Une plateforme de développement ne constitue certes pas un dépôt FAIR, sans compter que GitHub, propriété de Microsoft, n’offre pas de garantie d’indépendance. Mais sa structure permet d’y déposer les informations nécessaires à préparer un dépôt FAIR. Nous mettons ici en évidence les bonnes (et moins bonnes) pratiques et proposons quelques « incontournables FAIR4S » du dépôt de code sur Zenodo.
1. Findable (=localisable)
Le software et ses métadonnées sont faciles à trouver par les humains comme par les machines.
Pour être trouvée, chaque version du code doit être identifiée et localisable au moyen d’un identifiant pérenne. Lorsque le code est sur GitHub, le moyen le plus sûr est d’utiliser l’API qui dépose automatiquement chaque release sur Zenodo en lui attribuant un DOI distinct.
-> Mon code, sur la forge comme sur le dépôt, est accompagné d’un ReadMe qui indique le DOI conceptuel du projet et un DOI par version.
-> Pour le confort des fouilleurs humains, il est agréable de trouver l’adresse du code dans le corps même de l’article. En première page c’est encore mieux!
Dans notre étude :
Sur 57 articles,
- seuls 9 ont attribué un DOI à leur code, (tous via Zenodo), soit 16%.
- seuls 6 d’entre eux ont un ReadMe (11%).
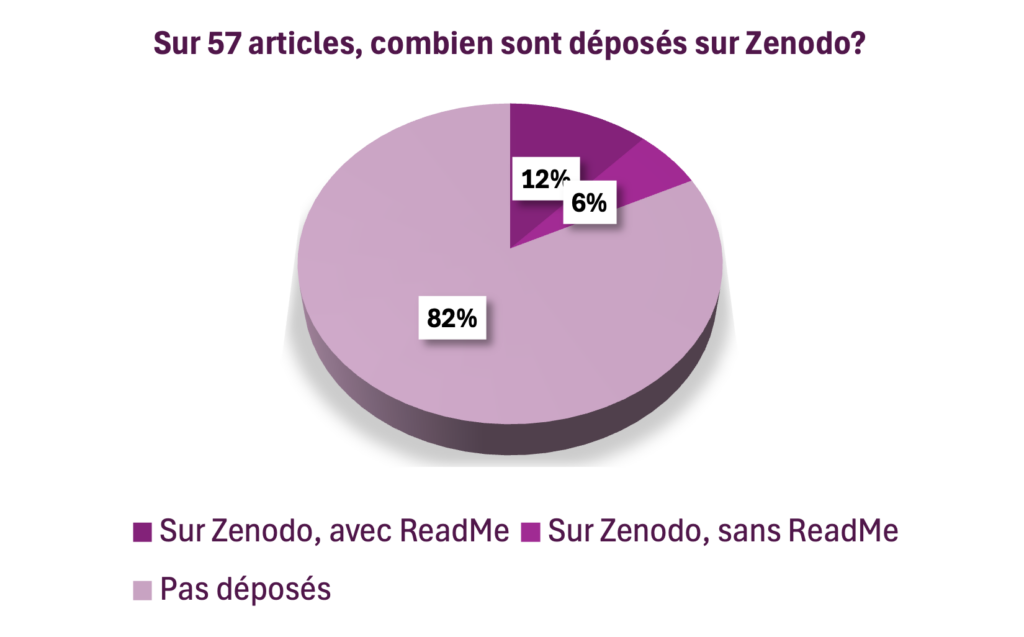

- 48 ont mis le lien dans le corps de l’article (texte ou notes) (84%).
2. Accessible (=techniquement)
Le software et ses métadonnées peuvent être récupérés au moyen de protocoles standardisés, ouverts, gratuits et implémentables universellement. Au besoin, ils permettent une procédure d’authentification. Les métadonnées sont accessibles même lorsque le software n’est plus disponible (grâce au DOI par exemple).
-> Mon code est accessible par un protocole ouvert tel que HTTPS.
-> Les fichiers sont dans des formats ouverts tes que csv, json et le ReadMe indique ces formats, l’installation et comment accéder aux dépendances
- Sur nos 57 articles, seuls 36 ont publié un ReadMe (63%).
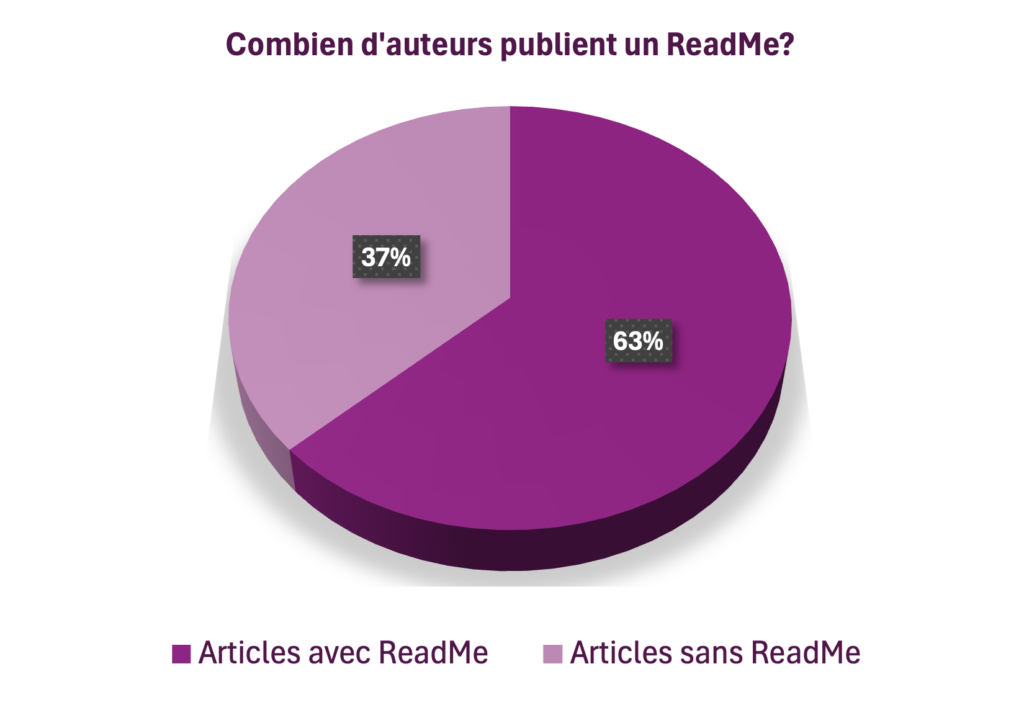
Et encore… le niveau de détail des métadonnées n’est pas homogène.
3. Interoperable
Le software doit être interprétable par d’autres softwares. A cet effet, le ReadMe doit décrire les formats et dépendances selon les ontologies et le vocabulaire contrôlé en vigueur dans la discipline.
-> Ainsi, un chercheur qui publie sur les enzymes devrait consulter un portail de standards, par exemple fairsharing.org, où il trouverait le schéma d’identifiant EC Number 8, créé en 1961 et maintenu par Portland Press, la maison d’édition de Biochemical Society[2].
-> Son software devrait produire des outputs en format ouvert (csv, json, etc.) afin que ses données respectent également les principes FAIR.
4. Reusable
La licence du software doit permettre sa libre réutilisation par un utilisateur ou codeur subséquent, à condition que ce dernier crédite l’auteur initial du software.
-> Il est ainsi recommandé de publier sous une licence dite permissive (p.x. « The MIT Licence » ou BSD), i.e. qui permet l’utilisation du code dans un futur logiciel propriétaire.
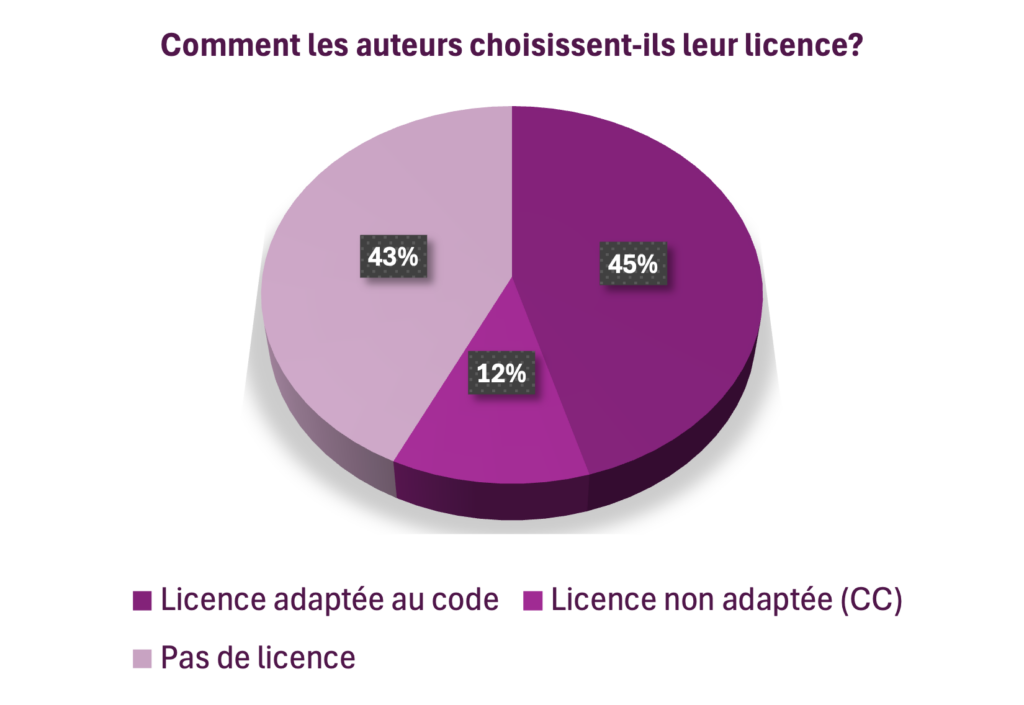
Dans tous les cas, pour choisir le sort des dérivés du code lors de leur réutilisation, les chercheurs doivent choisir une licence adaptée au code source. Or, dans notre corpus, on trouve encore beaucoup de licences Creative Commons, qui ont été conçues pour des fichiers textes, images et vidéos :
- Sur 83 mises à disposition quelque part sur le net (NB, un article peut être mis à disposition sur plusieurs plateformes) :
- 35 articles sont publiés sous des licences adaptées
- 9 sous une licence non adaptée au code (Creative Commons)
- 33 n’ont pas indiqué de licence
Conclusion
Notre analyse montre que si GitHub facilite la préparation d’un dépôt FAIR, la chaîne de partage demeure fragile. Les chercheurs oublient trop souvent de déposer leur code sur Zenodo et ne sont pas toujours au fait des enjeux juridiques du choix des licences. Les ReadMe sont trop souvent absents. Il est nécessaire de former les professionnels de l’open science afin qu’ils puissent accompagner et guider chercheurs et étudiants dans la publication de leur code.
Pour un aperçu des enjeux de la publication du code dans la recherche, vous pouvez consulter cette vidéo. Pour des conseils concrets sur la publication, vous pouvez consulter notre checklist FAIR4S.
Laisser un commentaire