

Par Alexandre Da Mota et Thomas Carreira
Introduction
Dans ce billet de blog, notre objectif a été de parcourir et de vulgariser différentes méthodes de machine learning. Nous commençons par aborder les principes fondamentaux du reinforcement learning qui nous permettent par la suite d’enchaîner sur l’imitation learning ainsi que deux de ses algorithmes, le behavioral cloning ainsi que DAgger. Nous poursuivons en expliquant les principes de generative adversarial network, mais également de l’inverse reinforcement learning ce qui nous permet de finir avec le generative adversarial imitation learning. Le but de ce billet est d’être informatif et non pas exhaustif, si vous souhaitez en apprendre plus sur les sujets abordés dans cet article, vous trouverez dans la bibliographie les ouvrages qui nous ont inspirés.
Reinforcement Learning
Pour bien comprendre le concept d’imitation learning (IL), il est intéressant de commencer à se pencher sur le reinforcement learning (RL), car ces deux méthodes ont le même objectif, mais diffèrent dans la manière de l’atteindre. Il est donc important de comprendre les concepts clés qui définissent ces deux méthodes, afin d’apprendre à les différencier convenablement.Le concept de RL s’articule autour d’un agent qui représente l’intelligence artificielle (IA) que l’on cherche à créer. Cet agent évolue dans un environnement avec lequel il va interagir. Chaque action que l’agent va entreprendre sur l’environnement va changer son état (state) et un state représente l’état de l’environnement à un instant t.
Figure 1 : Diagramme d’interaction entre l’agent et l’environnement dans un processus de décision Markovien (Markov Decision Process)
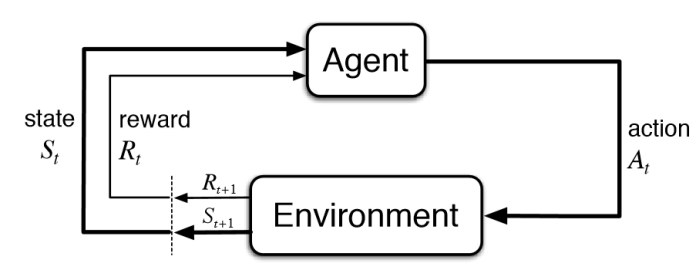
Source : SUTTON, Richard S. et BARTO, Andrew G., 2018. Reinforcement learning: an introduction. Second edition. Cambridge, Massachusetts : The MIT Press. Adaptive computation and machine learning series. ISBN 978-0-262-03924-6. Q325.6 .R45 2018
L’agent doit donc réaliser de nombreuses actions dans l’environnement afin de se rapprocher de son but. Cependant, son but, d’un projet à un autre, est rarement le même. Par exemple, dans le cadre d’une application de plans routiers, l’objectif de l’agent est de trouver l’itinéraire le plus rapide. En revanche, dans le cadre du jeu CartPole qui consiste à maintenir la barre (la tige beige) droite, l’objectif de l’agent est de faire bouger le cart (le bloc noir) de telle sorte à ce que la barre ne tombe pas.
Figure 2 : Représentation du jeu CartPole, en noir, le petit cart que l’agent doit faire bouger afin de maintenir en équilibre la barre beige.
![Introducing CartPole-v1 - Hands-On Q-Learning with Python [Book]](https://lh3.googleusercontent.com/i-4DlKugT9ineY4fAlS9mhew06bhWNlfL7izgKYq9Pa12P_3TZyBlKPloPKjNIY1GTRi4c0wrIipTYS7mRG0n4Zfa4i0_wz0DvKq1XcmkU0eOeoWOPlnsH9ul9iUNCcW5Njcu24M=s0)
Source : Introducing CartPole-v1 – Hands-On Q-Learning with Python [Book] [en ligne]. S.l. : s.n. [Consulté le 15 septembre 2021]. ISBN 9781789345803. Disponible à l’adresse : https://www.oreilly.com/library/view/hands-on-q-learning-with/9781789345803/a8a2cb05-8654-4cd1-b9c3-84d5c193de06.xhtml.
Maintenant, pour que les agents atteignent leur objectif, ils doivent réaliser plusieurs séries d’entraînements leur permettant de se familiariser avec leur environnement. Cette familiarisation en RL se traduit par une policy qui dicte à l’agent quel comportement avoir selon l’état dans lequel il se trouve. Pour trouver la policy la plus optimale, celle qui permet à l’agent d’atteindre son objectif, il va devoir pratiquer. L’agent va donc effectuer des séries d’action lui permettant de passer d’un état à un autre et ainsi de commencer à se familiariser avec la dynamique de l’écosystème. On peut voir la dynamique comme étant la probabilité que l’agent puisse passer d’un état à un autre. De plus, il existe les environnements déterministes, comme les échecs où l’on sait ce qu’il se passe lorsque l’on bouge un pion et les environnements stochastiques où chaque action à une probabilité qu’elle se réalise normalement.
En revanche, ce qui permet à l’agent de savoir s’il a effectué la bonne action sont les rewards (figure 1) ou récompenses en français. Une récompense est un nombre et selon les objectifs à atteindre cette valeur peut varier. Par exemple, dans le cas où l’agent serait dans un labyrinthe et devrait emprunter le chemin le plus court pour en sortir, il serait possible qu’à chaque pas, la récompense soit de 1 et l’objectif de l’agent serait de minimiser ce résultat. Selon les situations, l’agent essaye donc d’ajuster sa policy afin de minimiser ou de maximiser les récompenses dans le but d’obtenir le meilleur résultat.
Une fois le meilleur score atteint, l’agent aura trouvé l’optimal policy. Cependant, en RL, il peut s’avérer que ce système de récompense atteigne ses limites. Cela peut être particulièrement vrai dans des environnements où les récompenses se font rares, par exemple, un jeu où des récompenses ne sont reçues que lorsque le jeu est gagné ou perdu. Pour résoudre ce problème, il est possible de concevoir manuellement des fonctions de récompenses, qui fournissent à l’agent des récompenses plus fréquentes. Malgré tout, dans certains scénarios complexes comme l’apprentissage d’un véhicule autonome, la confection manuelle de telles fonctions peut s’avérer extrêmement compliquée voir impossible. C’est une des raisons qui vient motiver l’utilisation de l’imitation learning.
Imitation Learning
La notion de récompense en imitation learning (IL) n’existe plus, elle est remplacée par l’expert. Au lieu de s’orienter en se basant sur des récompenses, l’agent va devoir essayer de comprendre et de reproduire aussi fidèlement que possible les agissements de l’expert. Cette méthode est plus intéressante que la précédente pour le projet SimGait, car nous avons déjà les experts. Effectivement, les modélisations de marches des patients qui nous ont été transmises par les HUG, représenteront les experts. De plus, ils seraient trop fastidieux et potentiellement impossible d’allouer manuellement des récompenses à chacune des intéractions que l’agent pourrait effectuer.
Behavioural Cloning
La forme la plus simple d’imitation learning est le behavioural cloning (BC), qui se concentre sur l’apprentissage de la policy de l’expert en utilisant l’apprentissage supervisé. L’apprentissage supervisé a pour objectif d’entraîner un algorithme de telle sorte qu’il puisse prédire à quelle classe une instance appartient.
Par exemple, prenons un jeu de données décrivant des fleurs pouvant être des iris => setosa, versicolor ou virginica, ce sont les trois classes de notre jeu de données. Dans ce set de données, chaque instance est composée de cinq attributs. Les quatres premiers sont la longueur et largeur des pétales ainsi que la longueur et largeur des sépales. Le cinquième attribut est celui définissant la famille de l’iris et c’est cet attribut que l’on cherche à deviner. Un algorithme d’apprentissage supervisé va donc commencer par entraîner son classificateur à partir des données qui lui auront été fournies. Ces dernières ne seront pas labellisées, c’est-à-dire que l’attribut définissant la classe aura été extrait, car c’est ce dernier que l’on cherche à prédire. Afin de réaliser ces prédictions, il existe de nombreux algorithmes tels que Naive Bayes, K-nearest neighbor, Linear regression, … Comme dit précédemment, ces algorithmes vont devoir s’entraîner. Une fois entraînés, ils seront capables de réaliser des prédictions et pour calculer la précision de ces dernières, nous allons comparer leurs résultats avec les vraies valeurs. Ainsi, il sera possible d’établir un pourcentage permettant d’évaluer l’efficacité de l’algorithme.
Pour behavioural cloning, la méthode est plus ou moins la même. Les démonstrations de l’expert se présentent sous forme de paires d’état et d’action. L’objectif de l’agent va être de deviner à partir de l’état, quelle action, l’expert a exécutée. Pour y parvenir, l’agent va s’y prendre de la même façon qu’avec le problème de classification précédent qui concernait les iris. Il va donc à partir des états faire des prédictions sur l’action, puis la précision de l’algorithme sera calculée en comparant la prédiction avec la réalité. Cependant, behavioural cloning comporte une faille, car si l’agent se retrouve dans un état qui n’a pas été couvert par les démonstrations de l’expert, l’agent a de fortes chances de dévier et finir par se crasher.
Figure 3 : L’échantillon fourni par l’expert est représenté par les traits tirés bleu et l’agent qui tente de reproduire la trajectoire de l’expert est en rouge. On peut observer qu’à un certain point l’agent se retrouve dans un état qui n’avait pas été couvert par la démonstration de l’expert et finit donc par se crasher.
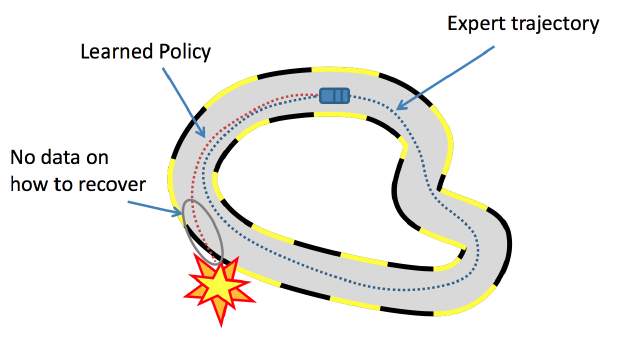
Source : AI, SmartLab, 2019. A brief overview of Imitation Learning [en ligne]. 19 septembre 2019. S.l. : s.n. [Consulté le 15 septembre 2021]. Disponible à l’adresse : https://smartlabai.medium.com/a-brief-overview-of-imitation-learning-8a8a75c44a9c.
DAgger
Pour contrer ce défaut, il existe un autre algorithme s’appelant DAgger (Dataset Agregation). L’objectif de ce dernier est de faire en sorte de couvrir plus d’états qu’avec behavioral cloning afin de s’approcher de l’exhaustivité. Afin d’y parvenir, DAgger va demander à l’expert de fournir une trajectoire étant composée de paires d’état et d’action comme vu précédemment. Ensuite, notre policy va être entraîné de la même façon qu’avec behavioral cloning. A ce point, nous avons une policy imitant le comportement de l’expert. Cependant, le set de trajectoire fourni par l’expert ne couvre pas toutes les possibilités. Nous allons donc exécuter notre policy novice afin de récolter une nouvelle trajectoire. De cette dernière, nous n’allons retenir que les états. L’expert va devoir compléter cette trajectoire en ajoutant les actions qu’il aurait effectuées dans chaque état.
Figure 4 : La ligne bleue représente la trajectoire de l’agent et chaque carré bleu représente un état. L’expert va donc montrer les actions (directions) qu’il aurait prises, s’il était dans chaque état.

Source : SCHULMAN, John, 2015. DAGGER and Friends. In : [en ligne]. S.l. 5 octobre 2015. [Consulté le 9 septembre 2021]. Disponible à l’adresse : https://rll.berkeley.edu/deeprlcourse-fa15/docs/2015.10.5.dagger.pdf.
Cette nouvelle trajectoire complétée sera ensuite ajoutée au set de trajectoires initiales. Pour finir, la policy novice va ensuite prendre le set de trajectoires mis à jour et de nouveau s’entraîner à reproduire le comportement de l’expert qui aura été étendu à d’autres états. Étant donné que le scénario ou l’agent se crachait a été corrigé par l’expert, la nouvelle version de la policy devrait être meilleure que la précédente. Cependant, il est possible que certaines situations n’aient pas encore été couvertes. La policy novice mise à jour va donc de nouveau être exécutée afin d’explorer de nouveaux états pas encore couvert par l’expert. Puis les étapes vues précédemment vont être réitérées jusqu’à obtenir la meilleure policy, celle qui couvrira potentiellement tous les états. Malgré tout, cette méthode possède toujours un problème, car pour corriger les trajectoires de l’agent, il nous est nécessaire d’interroger l’expert. Contrairement à behavioral cloning où nous n’avions besoin que de la trajectoire (état, action), cette méthode demande des interactions régulières avec l’expert. La prochaine méthode generative adversarial imitation learning (GAIL) reprend des concepts de l’imitation learning sans les désavantages vu précédemment.
Generative Adversarial Imitation Learning
GAIL est un algorithme sans modèle d’apprentissage par imitation qui permet d’imiter des comportements complexes dans des environnements encore plus complexes. C’est grâce à la combinaison des generative adversarial networks (GAN) et de l’inverse reinforcement learning (IRL) que GAIL peut fonctionner.
Generative Adversarial Networks
Les GAN sont des architectures de réseau neuronales qui ont pour objectif de résoudre des jeux d’imitation comme le deep fake. Le deep fake est une technique populaire de synthèse d’images basée sur de l’intelligence artificielle. Elle est plus puissante que la traduction traditionnelle d’image à image, car elle peut générer des images sans données d’entraînement appariées. L’objectif du deep fake est de capturer des caractéristiques communes à partir d’une collection d’images existantes et de trouver un moyen d’induire d’autres images créées avec ces mêmes caractéristiques. Les GAN nous offrent un moyen pour implémenter les deep fake (Tianxiang Shen, 2018). Aujourd’hui, plusieurs articles avec toutes sortes de problématiques éthiques liées au deep fake et à la vraisemblance de leurs résultats sont publiés. Une preuve de la puissance d’imitation du framework.
Fonctionnement
Un réseau GAN est composé de deux réseaux de neurones : un générateur et un adversaire (également appelé discriminant). Le rôle du générateur, qu’on appellera G, sera de créer une imitation (“fake”) et le discriminant, qu’on appellera D, devra évaluer ce fake et donner une “note” de vraisemblance sur la qualité de celui-ci. De ce fait, D indique à G qu’elles seraient les paramètres à changer pour améliorer l’imitation de G. L’objectif étant que D ne puisse plus faire la différence avec le résultat de G et une donnée authentique. Pour ce faire, on va donner un lot de données authentiques pour entraîner le discriminant à différencier une imitation d’une donnée authentique. Ensuite, le générateur crée une nouvelle imitation qui sera évaluée par D. Et ainsi, chacun son tour, les réseaux de neurones sont entraînés jusqu’à ce que le discriminant ne soit plus capable de différencier les deux.
Figure 5 : Schéma sémantique du fonctionnement des GAN où G est le générateur, Xtrain sont les données authentiques et D est le discriminant.

Source : DE CRISTOFARO, Emiliano, 2017. Figure 1: Generative Adversarial Network (GAN). [en ligne]. 2017. S.l. : s.n. [Consulté le 16 septembre 2021]. Disponible à l’adresse : https://www.researchgate.net/figure/Generative-Adversarial-Network-GAN_fig1_317061929.
On initialise G avec des valeurs aléatoires comprises entre 0 et 1. De ce fait, G crée une imitation qu’il transmet au discriminant, D. D qui, au préalable a reçu des données authentiques, compare l’imitation avec les authentiques et donne la probabilité que l’image reçue de G soit “fake”. Puis, grâce à l’algorithme de la rétropropagation du gradient, D informe des modifications à G en changeant les poids synaptiques des neurones afin d’améliorer son imitation. Les deux réseaux s’entraînent chacun leur tour : D s’entraîne à différencier une donnée authentique d’un “fake” et G, sur la base des résultats de D s’entraîne à créer une imitation.
Inverse Reinforcement Learning
L’Inverse Reinforcement Learning (IRL) répond au même problème que l’imitation learning. Comme vu précédemment, il est parfois quasiment impossible de réaliser manuellement la fonction générant les récompenses. Cette situation survient la plupart du temps lorsque l’environnement est trop complexe. Pour pallier ce problème, l’IRL va utiliser un expert comme pour l’IL. Cependant, au lieu d’essayer de reproduire le plus fidèlement possible le comportement de l’expert, l’IRL va plutôt tenter de deviner et de reproduire la fonction de récompenses de l’expert en analysant son comportement. Un des algorithmes les plus connus permettant d’atteindre cet objectif s’appelle maximum entropy. Ensuite, une fois que nous avons la bonne fonction de récompense, le problème se réduit à trouver la bonne policy et peut être résolue avec des méthodes d’apprentissage par renforcement standard. Malgré tout, cette méthode comporte quand même des failles. Tout d’abord, une policy peut être optimale pour de nombreuses fonctions de récompense différentes et certaines d’entre elles peuvent être dégénérées en ayant par exemple assigné zéro récompense à tous les états. De plus, l’IRL suppose que le comportement observé est optimal. Ce qui est une hypothèse forte, sans doute trop forte lorsque nous parlons de démonstrations humaines.
Nous allons maintenant aborder la dernière méthode d’apprentissage qui est Generative adversarial imitation learning.
Generative Adversarial Imitation Learning
GAIL applique tous les fondamentaux parcourus dans ce rapport. En effet, l’algorithme utilise une architecture GAN combinée à un apprentissage par renforcement inverse (IRL). Une des problématiques soulevées dans ce rapport, chapitre sur l’apprentissage par imitation, est le besoin de l’agent à se référer à un expert pour s’améliorer. Dans un environnement complexe, il est impossible d’avoir toutes les possibilités parcourues par l’expert donc, l’agent sera limité dans son apprentissage. Cet algorithme utilise l’architecture des GAN pour pallier cette problématique. En effet, le fait que le générateur ne soit jamais exposé aux données authentiques a permis de minimiser ce problème. Le discriminant apprend à distinguer les performances générées par l’agent à celles de l’expert jusqu’à ce qu’il en soit plus capable. Puis, grâce à l’apprentissage par renforcement inverse, l’agent établira une policy basée sur le résultat du discriminant. En effet, n’ayant pas accès à la récompense, l’algorithme essaie d’établir une policy directement depuis les données. Donc, grâce au résultat du discriminant, l’algorithme pourra établir un système de récompense et l’utiliser pour améliorer son choix d’action dans un état donné par l’environnement.
Sur la figure ci-dessous, on voit les deux réseaux neuronaux, le générateur et le discriminant. Dans le générateur, il y a l’environnement qui va fournir un état à l’agent. Celui-ci effectuera une action en fonction de l’état où il se trouve, cette paire (état/action) sera envoyée au discriminant qui comparera le pair généré par l’agent avec une paire authentique de l’expert. Le discriminant retourne la probabilité que la paire générée soit fausse. Cette probabilité sera retournée au générateur qui réglera les poids de l’état avant de tester une autre paire. Le résultat du discriminant sera utilisé comme signal de récompense pour établir un apprentissage par renforcement.
Figure 6 : Schéma sémantique du fonctionnement de GAIL

ZHOU, Yang, 2020. Figure 1. The structure of the proposed model generative adversarial… [en ligne]. 2020. S.l. : s.n. [Consulté le 16 septembre 2021]. Modifiée par Alexandre Da Mota, l’originale est disponible à l’adresse :
https://www.researchgate.net/figure/The-structure-of-the-proposed-model-generative-adversarial-imitation-learning-gated_fig1_344212933.
Conclusion
Grâce à ce billet de blog, nous avons pu comprendre les fondements de GAIL. Il va s’en dire que la partie technique reste à travailler, mais un bon chemin de compréhension sémantique à été parcouru. Il serait prétentieux de dire que tout est compris, car le sujet est tellement vaste. Chaque concept rapporte à un autre concept tout autant conséquent que celui qui le précède. Nous ne sommes qu’à une simple introduction du sujet, mais nous comprenons l’importance de fonder une base forte de compréhension avant d’attaquer une partie technique. Néanmoins, chacune de nos recherches permettent à ceux qui le veulent d’approfondir chaque sujet abordé dans ce billet de blog. La bibliographie en est le résultat.
Bibliographie
Reinforcement Learning
SUTTON, Richard S. et BARTO, Andrew G., 2018. Reinforcement learning: an introduction. Second edition. Cambridge, Massachusetts : The MIT Press. Adaptive computation and machine learning series. ISBN 978-0-262-03924-6. Q325.6 .R45 2018
Imitation Learning
RAVICHANDIRAN, Sudharsan, 2020. Deep Reinforcement Learning with Python – Second Edition [en ligne]. S.l. : s.n. [Consulté le 13 septembre 2021]. ISBN 978-1-83921-068-6. Disponible à l’adresse : https://hesge.scholarvox.com/catalog/book/docid/88902943.
ROSS, Stéphane, GORDON, Geoffrey J et BAGNELL, J Andrew, 2010. A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning. In : . 2 novembre 2010. pp. 9.
SCHULMAN, John, 2015. DAGGER and Friends. In : [en ligne]. S.l. 5 octobre 2015. [Consulté le 9 septembre 2021]. Disponible à l’adresse : https://rll.berkeley.edu/deeprlcourse-fa15/docs/2015.10.5.dagger.pdf.
Generative Adversarial Network
GOODFELLOW, Ian J., POUGET-ABADIE, Jean, MIRZA, Mehdi, XU, Bing, WARDE-FARLEY, David, OZAIR, Sherjil, COURVILLE, Aaron et BENGIO, Yoshua, 2014. Generative Adversarial Networks. In : arXiv:1406.2661 [cs, stat] [en ligne]. 10 juin 2014. [Consulté le 16 septembre 2021]. Disponible à l’adresse : http://arxiv.org/abs/1406.2661.
SHEN, Tianxiang, LIU, Ruixian, BAI, Ju et LI, Zheng, 2018. “Deep Fakes” using Generative Adversarial Networks (GAN). In : . 2018. pp. 9.
Inverse Reinforcement Learning
ABBEEL, Pieter et NG, Andrew Y., 2004. Apprenticeship learning via inverse reinforcement learning. In : Twenty-first international conference on Machine learning – ICML ’04 [en ligne]. Banff, Alberta, Canada : ACM Press. 2004. pp. 1. [Consulté le 31 août 2021]. Disponible à l’adresse : http://portal.acm.org/citation.cfm?doid=1015330.1015430.
ALEXANDER, Jordan, 2018. Learning from humans: what is inverse reinforcement learning? In : The Gradient [en ligne]. 20 juin 2018. [Consulté le 31 août 2021]. Disponible à l’adresse : https://thegradient.pub/learning-from-humans-what-is-inverse-reinforcement-learning/.
EVANS, Owain, 2018. Model Mis-specification and Inverse Reinforcement Learning – LessWrong. In : [en ligne]. 9 novembre 2018. [Consulté le 31 août 2021]. Disponible à l’adresse : https://www.lesswrong.com/posts/cnC2RMWEGiGpJv8go/model-mis-specification-and-inverse-reinforcement-learning.
ZIEBART, Brian D, MAAS, Andrew, BAGNELL, J Andrew et DEY, Anind K, [sans date]. Maximum Entropy Inverse Reinforcement Learning. In : . pp. 6.
Generative Adversarial Imitation Learning
GOODFELLOW, Ian J., POUGET-ABADIE, Jean, MIRZA, Mehdi, XU, Bing, WARDE-FARLEY, David, OZAIR, Sherjil, COURVILLE, Aaron et BENGIO, Yoshua, 2014. Generative Adversarial Networks. In : arXiv:1406.2661 [cs, stat] [en ligne]. 10 juin 2014. [Consulté le 15 septembre 2021]. Disponible à l’adresse : http://arxiv.org/abs/1406.2661.
HO, Jonathan et ERMON, Stefano, 2016. Generative Adversarial Imitation Learning. In : arXiv:1606.03476 [cs] [en ligne]. 10 juin 2016. [Consulté le 31 août 2021]. Disponible à l’adresse : http://arxiv.org/abs/1606.03476.
ORSINI, Manu, RAICHUK, Anton, HUSSENOT, Léonard, VINCENT, Damien, DADASHI, Robert, GIRGIN, Sertan, GEIST, Matthieu, BACHEM, Olivier, PIETQUIN, Olivier et ANDRYCHOWICZ, Marcin, 2021. What Matters for Adversarial Imitation Learning? In : arXiv:2106.00672 [cs] [en ligne]. 1 juin 2021. [Consulté le 31 août 2021]. Disponible à l’adresse : http://arxiv.org/abs/2106.00672.
Laisser un commentaire