

Avec le projet de recherche Ask_ArchiLab (HEG Genève), nous, Alexandra Paraschiv et Cheyenne Dubois, explorons comment des outils d’intelligence artificielle en open access peuvent transformer des archives audiovisuelles en ressources enrichies et exploitables.
Si l’Encyclopédie était un chantier collectif pour mettre en ordre les savoirs du XVIIIᵉ siècle, notre projet Ask_ArchiLab pourrait en être une version numérique : faire parler une vidéo patrimoniale contemporaine comme La fabrication du livre de la Bibliothèque nationale de France et l’inscrire, elle aussi, dans un réseau de connaissances. Au lieu de volumes reliés, nous travaillons avec un fichier vidéo ; au lieu de typographes et de graveurs, nous collaborons avec des outils open source d’intelligence artificielle, orchestrés pour que son, texte et image dialoguent.
De la vidéo brute à des images qui parlent
Au premier regard, nous disposons de peu d’informations concernant la vidéo de la BnF : un titre, une durée et quelques lignes de description. Pour approcher son contenu, nous commençons par la séparer en ses deux composantes : l’audio et l’image. Un outil IA (FFmpeg) extrait la piste sonore et découpe le flux visuel en centaines de cadres (frames) numérotés, comme si l’on transformait un film en livre d’images.
Sur ces images fixes, un moteur de reconnaissance optique de caractères (EasyOCR) lit ce que l’œil perçoit : titres, inscriptions visibles à l’écran, génériques, etc. C’est lui qui parvient à déchiffrer la célèbre page de titre de l’Encyclopédie et à récupérer, sur le générique final, la liste des personnes et institutions impliqués dans la réalisation du film. Les mots ne sont plus prisonniers de la vidéo : ils deviennent des lignes structurées, associées à chaque cadre, prêts à être réutilisés pour l’indexation ou l’analyse.
Écouter la voix, reconnaître les noms
Pendant que l’OCR lit l’image, un autre outil écoute. La piste audio est confiée à un modèle de reconnaissance vocale (Whisper) qui transcrit automatiquement la narration en texte horodaté. Sur notre vidéo d’environ cinq minutes, il produit plusieurs centaines de mots, avec une précision suffisante pour restituer correctement des noms comme Diderot, d’Alembert ou Gutenberg.
À partir de cette transcription, une bibliothèque de traitement automatique du langage (spaCy) repère les entités nommées (en anglais : NER pour Named Entity Recognition) : personnes, lieux, institutions. C’est ainsi que Denis Diderot, Jean Le Rond d’Alembert et Johannes Gutenberg émergent du texte comme des entités distinctes, que l’on peut ensuite relier à leurs identifiants dans Wikidata. Ces Q-IDs jouent le rôle de passeports numériques : Q448 pour Diderot, Q153232 pour d’Alembert, Q8958 pour Gutenberg.
Voir les objets, relier les modalités

La vidéo ne contient pas que des mots. Les plans montrent des caractères mobiles, des mains au travail, des livres en pile. Pour ne pas perdre cette information, nous faisons intervenir un modèle de détection d’objets (Yolo) qui balaye les cadres à la recherche d’éléments visuels récurrents : “personne”, “livre”, etc. Chaque détection est associée à une image précise, ce qui permet de dire : dans telle portion de la vidéo, une personne intervient, un livre est montré en gros plan.
Cette combinaison d’écoute (transcription), de lecture (OCR) et de vision (détection d’objets, correspondance image – texte) permet de construire une sorte de carte multimodale de la vidéo : pour chaque segment, nous savons à la fois ce qui est dit, ce qui est écrit à l’image et ce qui est montré.
Du matériau brut au graphe de connaissances
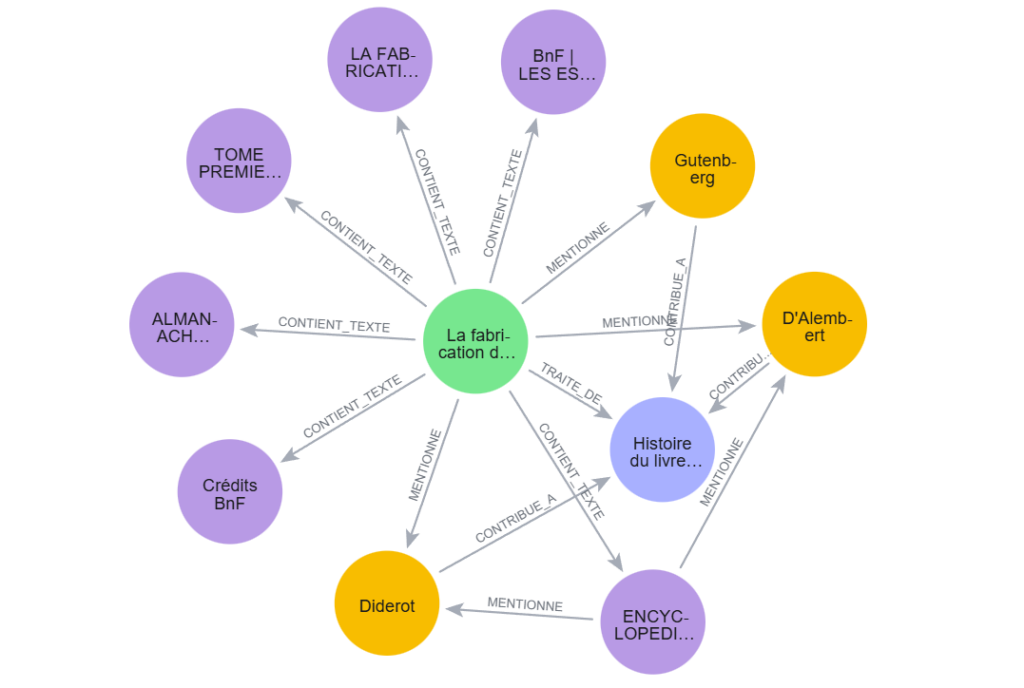
L’ensemble de ces métadonnées extraites est ensuite structuré dans des formats interopérables : fichiers texte pour la lecture humaine, CSV pour associer chaque cadre à ses fragments de transcription et leurs scores de confiance, fichiers JSON pour les entités nommées et leurs identifiants Wikidata. À partir de ces données enrichies, nous construisons un graphe de connaissances dans Neo4j : un nœud pour la vidéo, des nœuds pour les personnages historiques, pour la BnF, pour les concepts clés, et des relations qui forment une toile de liens.
Ce graphe peut paraître modeste avec quelques nœuds mais il change radicalement l’accès au contenu. Grâce aux identifiants partagés, ces nœuds se connectent à l’écosystème plus large du web de données : œuvres associées, encyclopédies en ligne, etc.
Des assistants, pas des oracles
L’ensemble de cette chaîne repose sur des outils IA open source, pilotés par des scripts et des commandes en Python que nous documentons soigneusement pour qu’ils puissent être réutilisés. Ces outils sont puissants, mais pas infaillibles : entités mal classifiées (confusion entre Johannes Gutenberg et le Project Gutenberg), objets mal identifiés dans certaines scènes, etc. Ce type de confusion rappelle l’importance du contrôle humain : l’IA propose, le documentaliste dispose ; c’est lui qui nettoie et structure l’information.
En travaillant sur ce cas d’étude, nous avons voulu montrer qu’une vidéo patrimoniale ne doit pas demeurer inexploitable. L’ironie serait grande : cette vidéo parle de l’Encyclopédie – un projet né pour rendre le savoir accessible, structuré, interconnecté – et elle-même resterait un contenu muet, impossible à explorer sans la visionner en entier. Notre démarche s’inscrit dans cet héritage des Lumières : ouvrir, structurer, relier.
Bibliographie
BIBLIOTHEQUE NATIONALE DE FRANCE. La fabrication du livre. Les Essentiels BNF [en ligne]. 2025. Disponible à l’adresse : https://essentiels.bnf.fr/fr/livres-et-ecritures/histoire-du-livre-occidental/efbeed25-e194-437d-ac46-ee9254f2d014-livre-epoque-moderne-16e-18e-siecles/video/77dc83cd-8a39-4b76-88f3-f667eb3e75f0-fabrication-livre [consulté le 20 novembre 2025].
FFMPEG, 2025. A complete, cross-platform solution to record, convert and stream audio and video. FFmpeg [en ligne]. 2025. Disponible à l’adresse : https://www.ffmpeg.org/ [consulté le 10 novembre 2025].
HEG, 2025 Ask_ArchLab: Enhancing Archival Practice through Artificial Intelligence technologies. Haute Ecole de Genève [en ligne]. Disponible à l’adresse : https://www.hesge.ch/heg/actualites/2025/askarchilab-enhancing-archival-practice-through-artificial-intelligence-technologies [consulté le 30 septembre 2025].
GITHUB, 2024. JaidedAI / EasyOCR. Github [en ligne]. 24 septembre 2024. Disponible à l’adresse : https://github.com/JaidedAI/EasyOCR [consulté le 20 novembre 2025].
GITHUB, 2025. Suraj5424 / Yolov8-Video-Object-detection. Github [en ligne]. 9 juillet 2025. Disponible à l’adresse : https://github.com/suraj5424/Yolov8-Video-Object-detection [consulté le 14 novembre 2025].
GITHUB, 2025. Openai / whisper. Github [en ligne]. 25 juin 2025. Disponible à l’adresse : https://github.com/openai/whisper [consulté le 10 novembre 2025].
NEO4J, 2025. Page d’accueil. NEO4J [en ligne]. 2025. Disponible à l’adresse : https://neo4j.com/ [consulté le 26 novembre 2025].
SPACY, 2025. Trained Models & Pipelines. spaCy [en ligne]. 2025. Disponible à l’adresse : https://spacy.io/models/fr [consulté le 21 novembre 2025].
WIKIMEDIA COMMONS, 2025. File:BNF – La fabrication du livre.webm. Wikimedia Commons [en ligne]. 2025. Disponible à l’adresse : https://commons.wikimedia.org/wiki/File:BNF_-_La_fabrication_du_livre.webm [consulté le 20 novembre 2025].
L’intelligence artificielle (Claude.ai et Perplexity.ia) a été utilisée à des fins de reformulation pour la rédaction de ce billet de blog ainsi que pour la rédaction de code Python pour l’utilisation des outils IA.
Laisser un commentaire