

Aujourd’hui, le big data nous permet de prédire le niveau de criminalité d’une ville (Bogomolov et al., 2014) ou d’anticiper des catastrophes naturelles telles que les tremblements de terre (DeVries et al., 2018). On peut se demander alors comment, à partir de données brutes, on arrive à de tels résultats ?
Le big data désigne « des ensembles de données devenus si volumineux qu’ils dépassent l’intuition et les capacités humaines d’analyse et même celles des outils informatiques classiques de gestion de base de données ou de l’information. » (CEA, 2017). Mais alors quels sont les nouveaux outils informatiques permettant de gérer ces ensembles de données si volumineux ? Et de quelle manière le calcul statistique et ses formules sont au cœur du phénomène big data ?
Utiliser les données, oui mais comment?
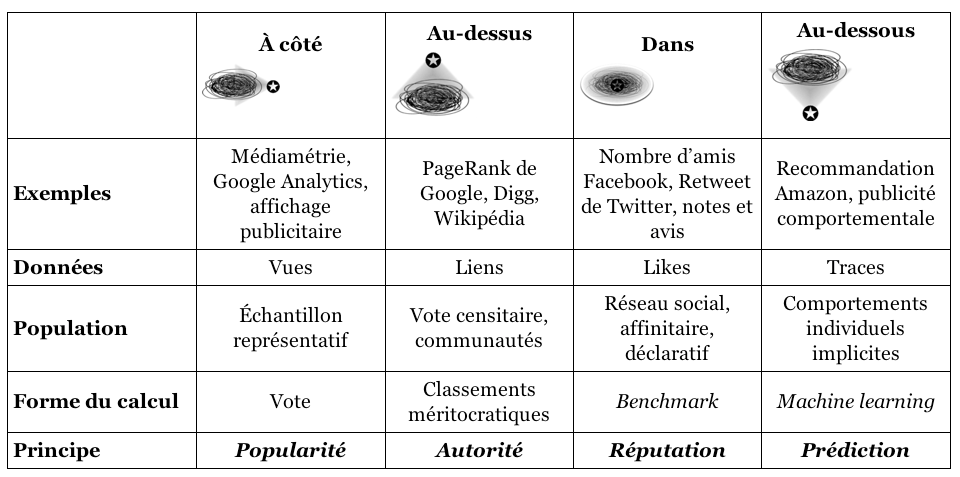
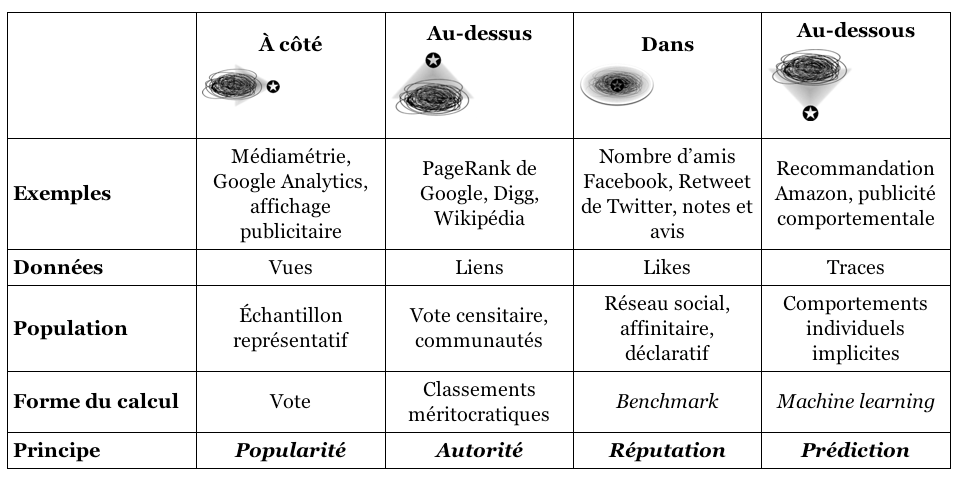
Dominique Cardon, sociologue et directeur du laboratoire de recherche Medialab de SciencePo identifie quatre familles de calcul numérique principal. Ces familles filtreraient, analyseraient et utiliseraient différemment les données du big data. Il illustre ces grandes familles par la métaphore géographique suivante : le calculateur peut se positionner à différents endroits de la donnée ou du champ de données observé, à côté, au-dessus, en dessous ou à l’intérieur tel que le montre le schéma suivant :
(source : http://revuecaptures.org/sites/default/files/Proulx_figure_8.1.png)
{kind=link}
- Si le calculateur se retrouve à côté, alors il va hiérarchiser en fonction du volume de personnes qui apprécient, écoutent ou likent. Ici les algorithmes calculeraient de l’audience et renverraient une hiérarchie de la popularité. Mais cela est critiqué car la popularité n’est pas garante de la valeur de l’information et cette popularité n’est mesurée qu’au nombre de clic.
- Si le calculateur se retrouve au-dessus, alors l’algorithme classe les sites en fonction de leurs citations par d’autres sites eux même cités par d’autres. Il y a une réelle hiérarchie qui se crée entre les sites. Ce système est critiquable par beaucoup d’aspects. L’algorithme d’autorité représente un terrain en mouvance constante où les techniques de détournement de ce système sont nombreuses et constamment réinventées. Améliorer le classement d’un site dans les moteurs de recherche représente un immense marché sur le web sans garanti de fiabilité de l’information.
- Si le calculateur se trouve à l’intérieur du monde qu’il décrit : c’est le web social, avec un classement de l’information personnalisé en fonction des données présentes sur les profils des personnes sur les réseaux sociaux. « De niche en niche, l’information circule alors par cercle d’affinité » (Cardon, 2018) ce qui incrémente la réputation d’une information et accélère la vitesse de diffusion. Ici on parle de modèle lié à la réputation avec cette nouvelle forme de visibilité.
- Si le calculateur se retrouve au-dessous du monde qu’il veut décrire, il le fait alors avec des algorithmes qui fonctionnent sous un modèle prédictif. Ce modèle utilise non pas les données que les gens fournissent sur les réseaux sociaux et autres mais enregistre la trace de leur comportement. Il semblerait alors que les informations des traces seraient plus véridiques que ce que la personne raconte de ce qu’elle fait sur les réseaux. Mais cela reste discutable. L’exploitation de ces données n’est pas explicite et le degré de fiabilité de ces traces reste incertain.
La machine algorithmique est loin d’être neutre.
En effet, avoir connaissance de ces différents principes et de leurs mécanismes est primordial pour les appréhender. Cela nous permet alors de nous mettre à distance et de se demander si ces transformations pourraient avoir des effets sur les comportements humains. En effet, l’humain cherche sans arrêt à se comparer et s’améliorer. Ces outils de calcul sont devenus les nouveaux critères d’évaluation du monde qui nous entoure. Il est donc encore plus primordial d’en connaître les mécanismes et leurs enjeux. On ne calcule pas pour objectiver mais pour engager les individus à améliorer leur performance. (Cardon, 2018). Cela alimente finalement un modèle comportementaliste encore peu représentatif de l’homme dans sa globalité.
Pour terminer, nous pouvons rappeler les mots de Cathy O’Neil dont le livre publié en 2016 « Weapons of Math Destruction » vient d’être traduit et publié en français. Lanceuse d’alerte, elle est mathématicienne et interpelle sur les notions d’éthique et de responsabilité que nous allouons aux algorithmes (Cario, 2018). Est-ce que la notion de responsabilité est quantifiable aux yeux des algorithmes ? Peut-on traduire cette notion en terme numérique ? Et si oui, quelle note donnerions-nous ? Et comment traduire celle-ci dans un code informatique fiable et contrôlable ? Ces questions primordiales sont au cœur des sciences des données et de l’information où le big data et ce que l’on en fait est plus que jamais porteur du sens que l’on veut donner, au monde de demain.
Bibliographie :
BOGOMOLOV, Andrey, LEPRI, Bruno, STAIANO, Jacopo, OLIVER, Nuria, PIANESI, Fabio et PENTLAND, Alex, 2014. Once Upon a Crime: Towards Crime Prediction from Demographics and Mobile Data. In : [en ligne]. 10 septembre 2014. [Consulté le 26 novembre 2018]. Disponible à l’adresse : https://arxiv.org/abs/1409.2983.
CARDON, Dominique, 2018. Du Big Data au marketing comportemental. In :
Matières à penser avec Serge Tisseron, France Culture [en ligne]. 25 mai
2018. [Consulté le 24 novembre 2018]. Disponible à l’adresse : https://www.franceculture.fr/emissions/matieres-a-penser-avec-serge-tisseron/du-big-data-au-marketing-comportemental.
CARIO, Erwan, 2018. Cathy O’Neil : «Les algorithmes créent leur propre réalité». In : Libération.fr [en ligne]. 16 novembre 2018. [Consulté le 26 novembre 2018]. Disponible à l’adresse : https://www.liberation.fr/debats/2018/11/16/cathy-o-neil-les-algorithmes-creent-leur-propre-realite_1692515.
CEA, 2017. Conférence : voyage au coeur du Big Data. In : CEA/Médiathèque [en ligne]. 5 juillet 2017. [Consulté le 26 novembre 2018]. Disponible à l’adresse : http://www.cea.fr/multimedia/Pages/videos/culture-scientifique/technologies/conference-big-data.aspx.
DEVRIES, Phoebe M. R., VIÉGAS, Fernanda, WATTENBERG, Martin et MEADE, Brendan J., 2018. Deep learning of aftershock patterns following large earthquakes. In : Nature. 1 août 2018. Vol. 560, n° 7720, p. 632‑634. DOI 10.1038/s41586-018-0438-y.
Laisser un commentaire